C++
Someone who is sophomoric about concepts and reasoning may try things randomly, and wastes a lot of time.
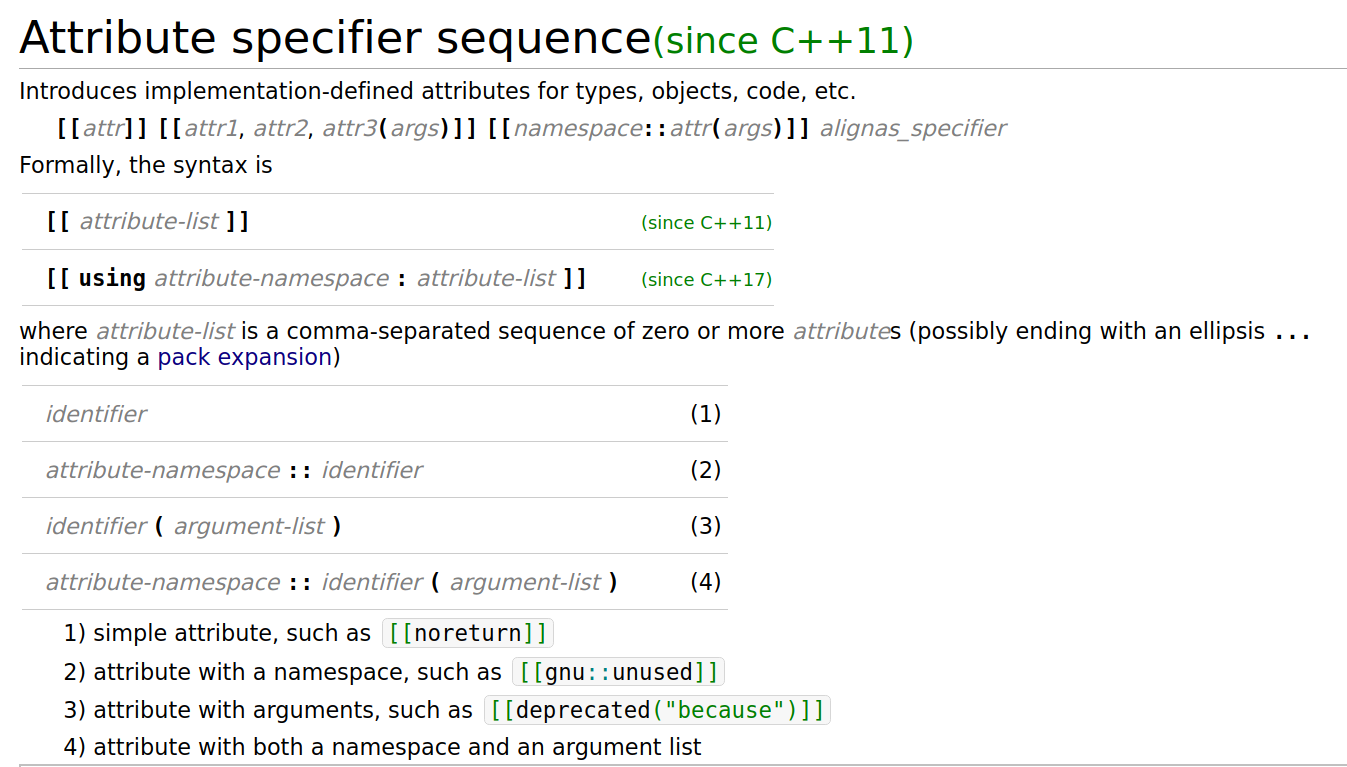
Attribute
使用场合:如想在编译时告知开发者某个函数即将deprecated,则使用
deprecated属性(当程序中调用这个函数时,编译期时则会弹出相关的信息)
Class
在对类进行实例化时,先会对数据成员进行初始化,初始化的优先级为:
初始化列表,类内初始化。换句话说初始化列表会替换类内初始化的行为。(@ref)
#include <iostream>
using namespace std;
class Test {
public:
Test() : var_(3) {
cout << var_ << endl; // 输出3
}
int var_ = 1;
};
int main() {
Test test;
}
成员函数(
member function)和数据成员(data member)是分开存储的;只有实例属性是存放在对象上的空类的大小为1,是为了保证每个(空)对象都有独一无二的内存地址,以使编译器区分他们
函数体:
Access Right
Inherit
— |
public |
protected |
private |
|---|---|---|---|
公有继承 |
public |
protected |
不可见 |
私有继承 |
private |
private |
不可见 |
保护继承 |
protected |
protected |
不可见 |
公有继承:继承的
public,protected成员保持原来的访问权限;子类无法访问基类的prviate成员保护继承:继承的
public,protected成员变为protect成员;子类无法访问基类的prviate成员私有继承:继承的
public,protected成员变为继承类的private成员;子类无法访问基类的prviate成员
Constructor
创建一个类时编译器至少给一个类添加如下特殊的函数,
默认构造函数(函数体为空,无参);默认拷贝函数,对属性进行值拷贝(浅拷贝);赋值运算符(assignment operator),对属性进行值拷贝构造函数分类:
类型 |
描述 |
案例 |
|---|---|---|
(类型)转移构造函数( |
A constructor that is not declared with the specifier explicit and which can be called with a single parameter (until C++11) is called a converting constructor. |
— |
|
有 |
— |
拷贝构造函数( |
调用构造函数时有实参(实参为同类型的对象) |
|
目标构造函数 / 委托构造函数 |
— |
— |

#include <iostream>
using namespace std;
class Foo {
public:
// 构造函数和析构函数无返回值
Foo() { std::cout << "调用默认构造函数" << endl; }
Foo(const Foo &) { std::cout << "调用拷贝构造函数" << endl; }
Foo(Foo &&) { std::cout << "调用移动构造函数" << endl; }
void operator=(const Foo &foo) { std::cout << "调用拷贝赋值函数" << endl; }
void operator=(Foo &&foo) { std::cout << "调用移动赋值函数" << endl; }
Foo(int x) { std::cout << "调用有单一参数的构造函数" << endl; }
// error : conversion from ‘int’ to non - scalar type ‘Foo’ requested private:
};
int main() {
auto A = Foo(); // 默认构造(default constructor)
auto B = A; // 拷贝构造(copy constructor)
auto C = Foo(std::move(B)); // 移动构造(move constructor)
Foo D; // 默认构造(default constructor)
D = B; // 拷贝赋值(copy assignment)
D = std::move(B); // 移动赋值(move assignment)
Foo E(3); // 调用有单一参数的构造函数
Foo F = 3.0; // 调用有单一参数的构造函数(此处可视为一种类型转换),加上explict的话则禁止隐式地转换
return 0;
}
Converting
声明时
explicit和能够用一个实参调用的构造函数(C++11之后只看有没有explicit了)即为类型转换构造函数(converting constructor)转移构造函数描述了一个隐式类型转换的函数(该函数能将实参类型的对象转换(
implicit conversion)到类类型对象)可以通过
explicit禁止类型的隐式转换
class Test {
public:
explicit Test(int i) {
}
};
int main() {
Test test = 10; // error:禁止类型的隐式转换
}
Copy
// b为T类型
T a = b; // 拷贝初始化
T a(b); // 直接初始化
为什么拷贝构造函数不能使用传值的参数?
因为会无限递归地触发拷贝构造函数
Default
默认构造函数:不需要提供实参就能调用的构造函数当类中没有提供任何构造函数时,且满足一定条件下(如数据成员没有引用),编译器将会隐式提供一个默认构造函数
使用默认构造时要避免
most vexing parse,即编译器将对象的初始化解析为函数声明。
using namespace std;
class Test {
public:
Test() = default;
};
int main() {
Test test; // ok
Test test0{}; // ok
Test test1(); // most vexing parse
}
Delegating
委托构造放在成员初始化列表中(当前仅有它一个成员)
用于复用构造函数的逻辑
#include <iostream>
using namespace std;
class Test {
public:
Test(int i) : Test() {
std::cout << "simple constructor" << std::endl;
}
Test() {
std::cout << "delegating constructor" << std::endl;
}
};
int main() {
Test test(1);
}
// output:
// delegating constructor
// simple constructor
Move
接收右值引用的构造函数
#include <vector>
#include <iostream>
#include <cassert>
using namespace std;
int main() {
std::vector<int> v{1, 2, 3, 4, 5};
std::cout << "pre-move: " << (void *) (v.data()) << std::endl;
std::vector<int> v2(std::move(v));
assert(v.empty());
std::cout << "post-move: " << (void *) (v.data()) << std::endl;
std::cout << (void *) (v2.data()) << std::endl;
return 0;
}
// pre-move: 0x5628b59daeb0
// post-move: 0
// 0x5628b59daeb0
Const Function
常成员函数,说明在该成员函数内不能修改成员变量(在成员属性声明时加关键词mutable,在常函数中则可以修改)
Assignment Function
一般来说返回值为自身的引用,用于保持连等的操作
struct Str {
Str &operator=(const Str &str) {
this->val = str.val; // 拷贝赋值
return *this;
}
Str &operator=(Str &&str) {
this->val = str.val; // 移动赋值
return *this;
}
int val = 0;
};
Compiler Action
如果自定义了构造函数,编译器不会提供默认构造函数(无参默认构造函数),但会提供默认拷贝构造函数;如果定义了拷贝构造函数,则编译器不会提供其他构造函数
总的来说,至少会有一个拷贝构造函数
Class Inherit
基本语法
class class_name : public base_class1, private base_class2
{
// todo
};
类函数声明和构造函数
#include <iostream>
using namespace std;
class Test {
public:
Test() : num_(3) { // 自定义无参构造函数
cout << num_ << endl;
}
int num_ = 1;
};
int main() {
Test t0(); // 类函数声明,不调用构造函数
Test t1; // 输出3
return 0;
}
Member
Static member
通常情况下,类内声明静态数据成员(有
static修饰),类外定义数据成员(无static)
class X { static int n; }; // declaration (uses 'static')
int X::n = 1; // definition (does not use 'static')
C++17后加入内联可以进行类内定义
struct X
{
inline static int n = 1;
};
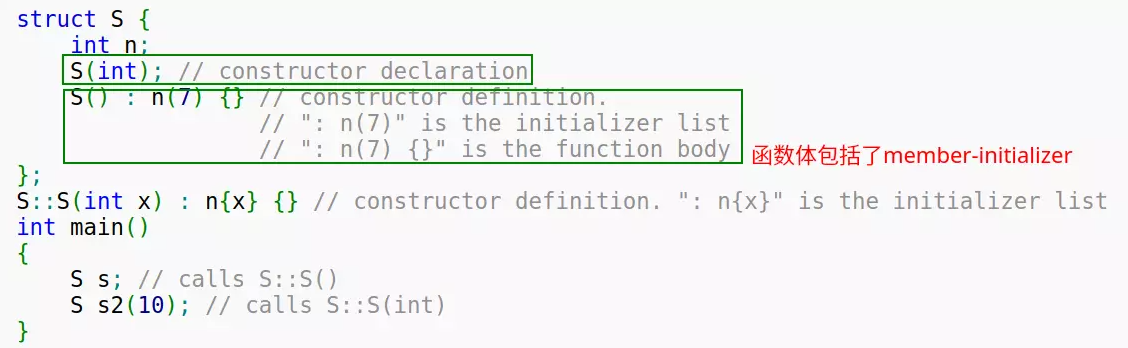
Member Initializers List
// constructor definition
ClassName([param-list]) <function-body[member-initializers-list]/brace-init-list>
备注
expression-list属于函数定义的函数体部分
struct S {
int n;
S(int); // constructor declaration
S() : n(7) {} // constructor definition.
// ": n(7)" is the initializer list
// ": n(7) {}" is the function body
};
S::S(int x) : n{x} {} // constructor definition. ": n{x}" is the initializer list
int main()
{
S s; // calls S::S()
S s2(10); // calls S::S(int)
}
Type
LiteralType
构造函数具备
constexpr specifier则其实例化的对象类型为LiteralType字面值类型包含了:
cv-qualified class type,其具备以下属性:具备平凡析构函数(until C++20);具备
constexpr修饰的析构函数(since C++)至少含有一个
constexpr修饰的构造函数(可能带模板),另外该构造函数不能是拷贝或移动构造函数
Virtual Function
虚函数的引入是为了更好的开发和维护,满足对拓展关闭, 对修改开放的原则
Abstract Class
声明了一个纯虚函数或继承了一个纯虚函数(在实际开发中,不会实例化父类,父类的虚函数没有实现的必要,所以引入纯虚函数)但是未提供实现的类(有纯虚函数但没有实现的类);抽象类无法实例化。(只是含虚函数的类是可以实例化的)
Abstract Class可作为Concrete Class的基类接口类(
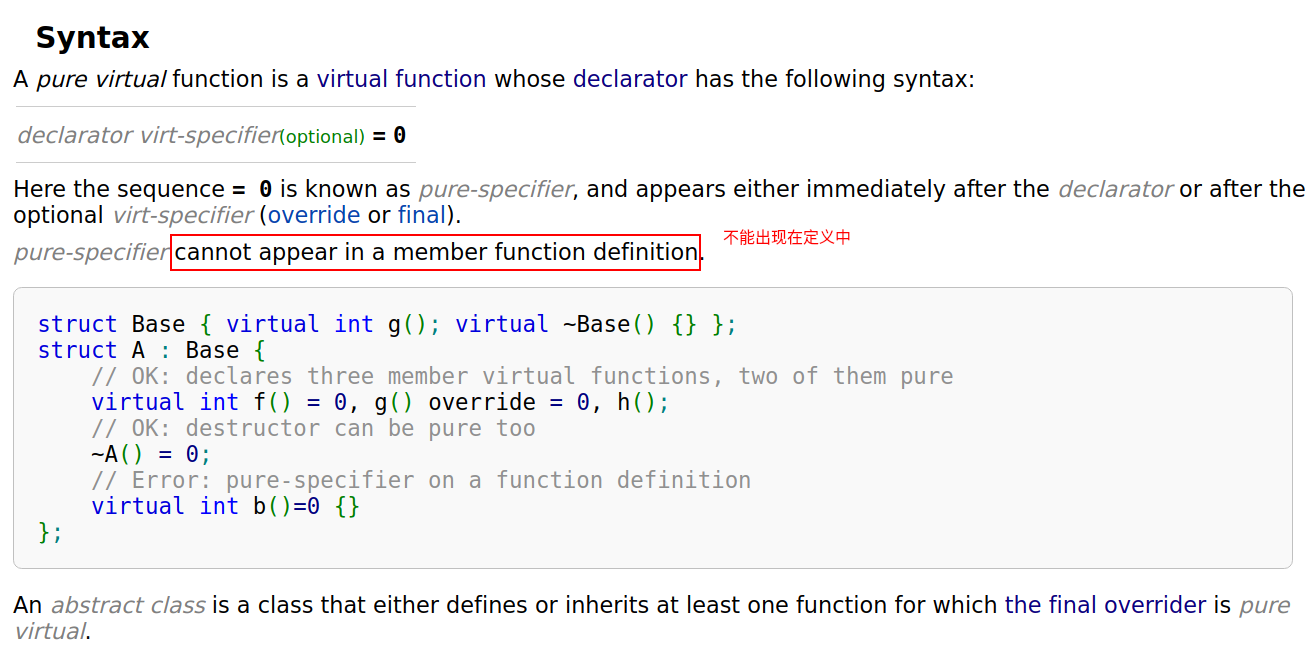
interface class):成员中仅有虚函数的类纯虚函数:声明虚函数的基础上加上一个等于0
declarator virt-specifier(optional) = 0
纯虚函数的修饰符(
sequence=0)不能出现在定义中
虚函数是一种特殊的成员函数,其实现能被子类重写(
override)带虚函数的类不能实例化
#include <iostream>
using namespace std;
class Base {
public:
virtual void test();
};
int main() {
/*
* ERROR: undefined reference to `vtable for Base'
*/
Base base;
}
#include <iostream>
using namespace std;
class Base {
public:
virtual void test();
};
class Children : public Base {
public:
void test() { cout << "hello" << endl; }
};
int main() {
/*
* ERROR:undefined reference to `typeinfo for Base'
*/
Children children;
children.test();
}
父类允许对纯虚函数提供类外实现,允许在子类中调用父类的纯虚函数(父类不可以调用,因为该父类不可以被实例化)
#include <iostream>
using namespace std;
class Base {
public:
virtual void test() = 0;
};
void Base::test() {
cout << "纯虚函数可以提供类外实现" << endl;
}
class Children : public Base {
public:
void test() { cout << "hello" << endl; }
};
int main() {
Children children;
children.test();
// 父类的纯虚函数可以被子类调用
children.Base::test();
}
只有非静态成员函数和非构造函数才能声明为虚函数
虚析构函数是为了用父类的指针释放子类对象
Compiler
对于一个有
虚函数实现的类,编译器会添加一个隐式数据成员即虚函数指针,虚函数指针指向虚函数表,虚函数表中存放了当前对象重写的和没重写的各个虚函数的地址。动态多态就是调用函数的地址在运行期进行确定。当编译器看到通过基类指针或基类引用调用虚函数时,不会直接确定函数的地址(
静态联编),而是进行动态联编,程序在运行期的时候,确定基类指针或引用对象的真实类型(比如说是派生类对象),并依次找到虚指针、虚函数表,待调用的虚函数的入口地址;最后根据函数入口地址执行虚函数代码。
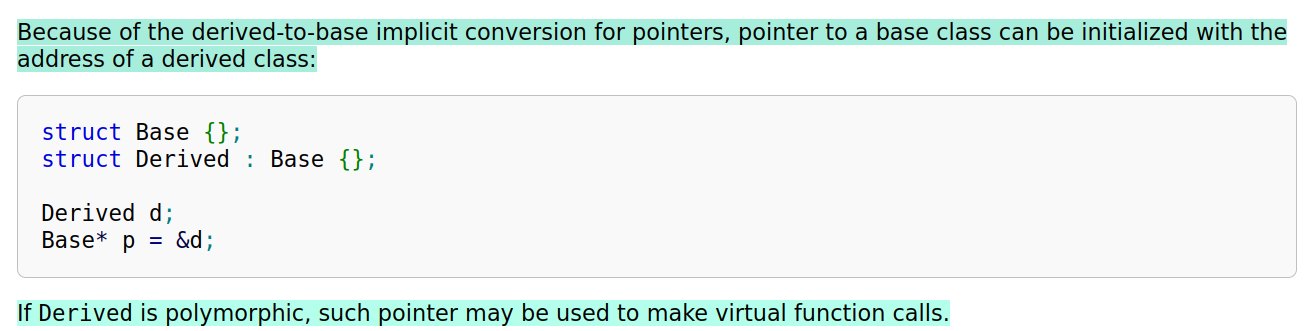
静态绑定和动态绑定函数
#include <iostream>
using namespace std;
class Animal {
public:
void speak() { cout << "动物在叫" << endl; } // 表明这个函数需要运行期确定
};
class Cat : public Animal {
public:
void speak() { cout << "猫在叫" << endl; }
};
void test01() {
Cat cat;
// 父类指针指向子类对象 / 给子类对象起父类引用别名
Animal &animal = cat;
animal.speak();
}
int main() {
test01();
return 0;
}
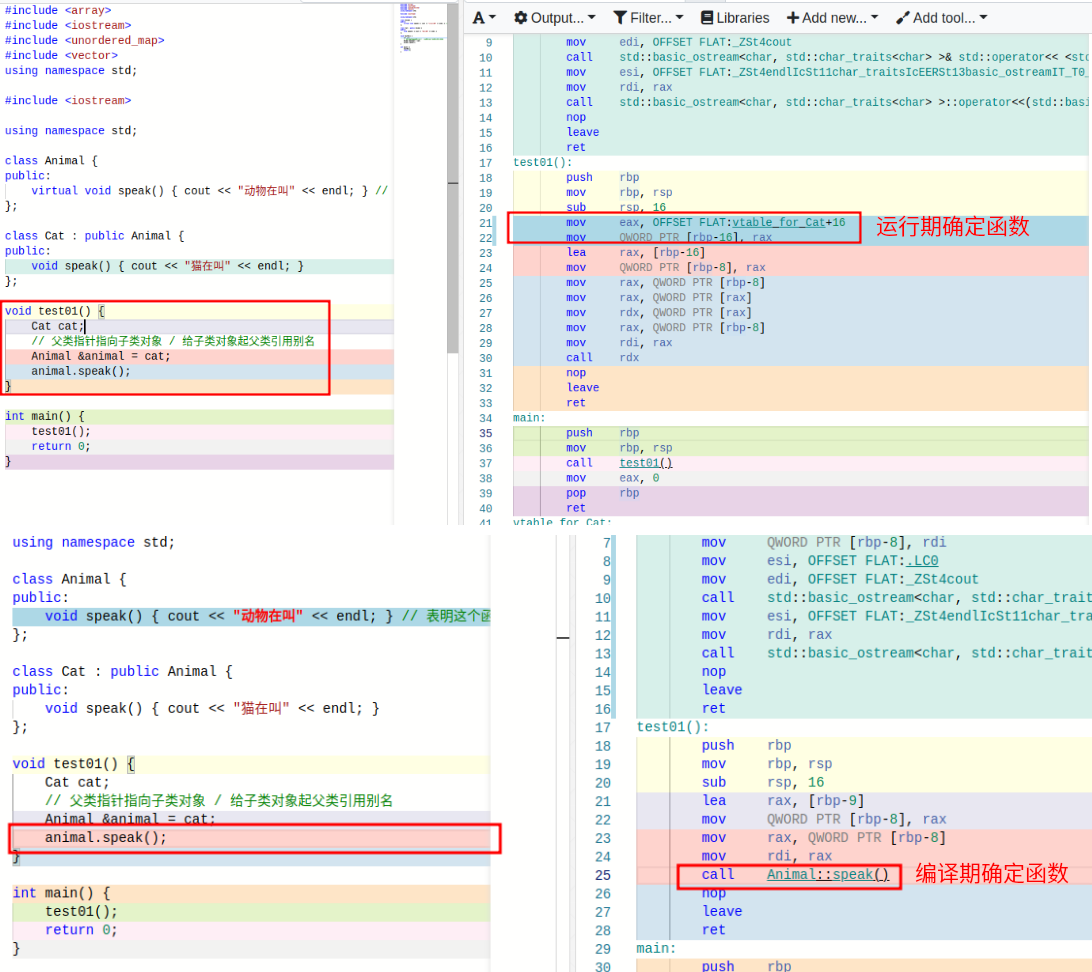
This Pointer
this指针是一个隐含于每一个非静态成员函数中的特殊指针,它指向调用该成员函数的那个对象;对一个对象调用其成员函数时,编译器先将对象的地址赋给this指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式地使用this指针this指针不是一个常规的变量,而是一个右值,不能取地址即
&this一般用来解决名称冲突:区分同名的形参;二来通过返回对象本身(
return *this),实现链式编程
Container Adapter
修改一个 底层序列容器,使其表现出新的功能和接口,比如stack 使deque表现出了先进后出的栈功能
容器适配器有
stack,queue,priority_queue
#include <deque>
#include <iostream>
#include <list>
#include <stack>
#include <vector>
using namespace std;
int main() {
// stack的构造
stack<int> stackA;
stack<int, deque<int>> stackB; // deque is the default container
stack<int, vector<int>> stackC;
stack<int, list<int>> stackD;
return 0;
}
Exception
使用
throw抛出异常,try-catch block捕获异常构造函数中如果抛出了异常,则其异常会被隐式的传递回一层栈帧(会自动添加
throw)为了避免异常抛出而导致分配的内存没有被释放,则一般倾向于构建的对象使用智能指针进行管理
Entity
c++程序中的实体包括值(
value),对象(object),引用(reference),函数(function),类型(type),模板(template)预处理宏(
prepocessor macro)不是c++实体(有人从它不是c++语法的内容去理解)
Expression
操作数(
operand)和操作符(operator)的组合,可以求值(evaluation),通常会返回求值结果
x = 3 // 表达式
x = 3; 语句
// void fun() {}
fun() // 该表达式没返回求值结果
expression evaluation(求值是个宽泛的概念,不一定是算术运算)
ID expression:该表达式只包含标识符,其结果为其具名的实体(
entity)
Lambda
一般构建可调用对象(callable object)可以通过对类的函数调用()操作符(operator)进行重载来构建,但自己写起来比较长,所以有了lambda表达式这种简化和灵活的写法(为了更加灵活的实现可调用对象)。匿名表达式可以认为是一种语法特性,该表达式会被编译器翻译为类进行处理;能够用来生成一个可调用对象(该对象的类型是一个类)/又或者说构建一个不具名的函数对象,同时该对象能够使用(捕获capture)该函数对象所在域的变量(这样的对象又称为:closure)
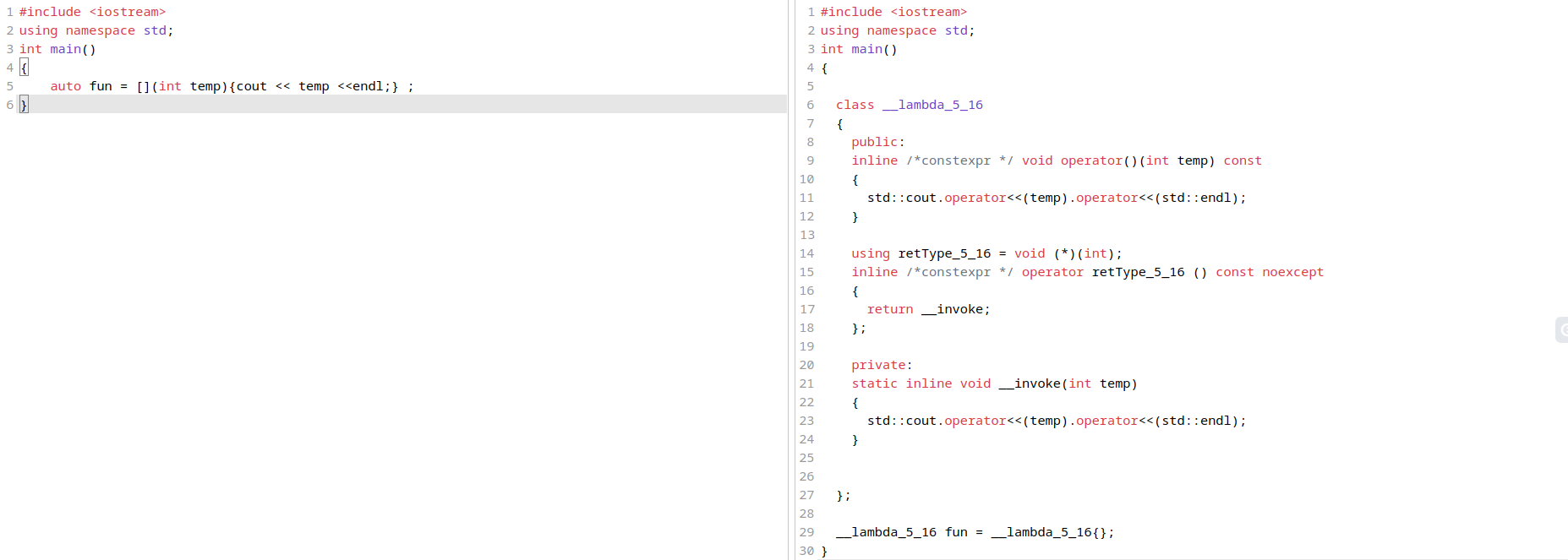
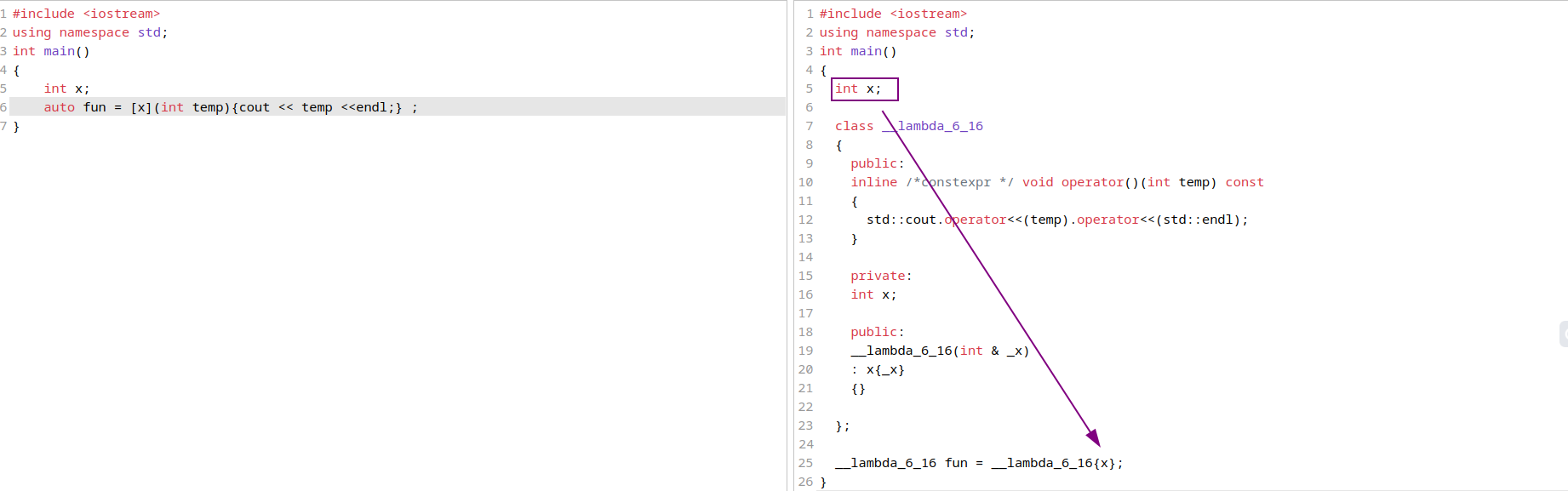
有关捕获,个人理解是描述了可以在
function body使用的外部变量,具体来说即构建的函数对象所在域的变量
Value category
泛左值、纯右值和将亡值实际上就是表达式
根据表达式的取值(evaluation)结果进行分类,就能得到泛左值、纯右值和将亡值若干类别
类别 |
概念 |
— |
|---|---|---|
泛左值 |
其取值标识了一个对象或者函数 |
可取址;可修改的左值可以放在内置赋值操作符左边; |
纯右值 |
其取值能对一个对象进行初始化 |
不可取址; |
将亡值 |
资源能够被复用的泛左值 |
— |
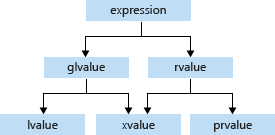
(作用:明确了编译器管理对象的规则)The value categories are the basis for rules that compilers must follow when creating, copying, and moving temporary objects during expression evaluation. @ref
在过去,左右值的区别比较容易,处于赋值语句左边的操作数为左值,处于赋值语句右边的操作数为右值。但放在现在是不恰当的,比如说
const int a = 1; // a是左值,但是不能放赋值语句左边,因为不可修改
泛左值:变量名(不管其是什么类型)和函数都是泛左值
const的左值引用,虽然能接收左值也能够接收右值,缺点是不能够对对象进行修改;右值引用作为形参更灵活,可以使用std::move()作为中介接收左值和右值
void fun(const int&) {}
int main() {
fun(4);
int temp = 4;
fun(temp);
}
字面值常量为左值,可取地址
&"hello_wolrd"
Side Effect
c++11 draft - 1.9.12: Accessing an object designated by a volatile glvalue, modifying an object, calling a library I/O function, or calling a function that does any of those operations are all side effects, which are changes in the state of the execution environment. Evaluation of an expression (or a sub-expression) in general includes both value computations (including determining the identity of an object for glvalue evaluation and fetching a value previously assigned to an object for prvalue evaluation) and initiation of side effects. When a call to a library I/O function returns or an access to a volatile object is evaluated the side effect is considered complete, even though some external actions implied by the call (such as the I/O itself) or by the volatile access may not have completed yet.
Function
Abbreviated function template
20标准引入了更简洁的模板声明,即使用在函数签名中使用
auto,但在定义的地方使用类型时比较麻烦

template <typename T>
void print_container(T set) {
for (auto &element : set) {
cout << element << " ";
}
cout << endl;
}
// 等价
void print_container(auto set) {
for (auto &element : set) {
cout << element << " ";
}
cout << endl;
}
Call
函数的调用分为若干个步骤,先是名称查找(
name lookup),编译器看是否有这个symbol;然后是模板实参推导(template argument deduction),之后是重载决议/解析(overload resolution),再是判断是否有充足的访问权限(access labels),再是函数模板特化(function template specialization),再是visual dispatch,再是deleting functions其中重载决议,就是在候选的函数中找到最合适可调用的函数
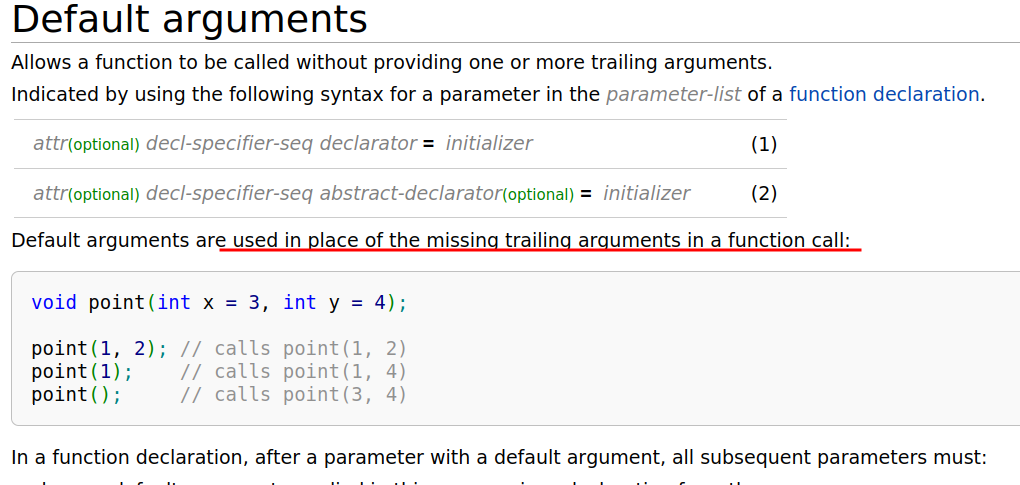
Default Argument
from c++98
默认实参不能在函数声明和实现中同时出现
某个位置参数有默认值后,则从这个位置往后从左到右到必须有默认值
Friend
友元函数能够让一个函数或一个类能够访问某个类的protected或private的成员,只需要在这个类定义中声明友元函数。
Inline
在开发中使用内联一方面是为了性能提升,减少函数调用的开销(栈帧的构造和销毁),另一方面是这边有个头文件,头文件里面包含了函数的定义,在链接阶段可能就有符号重定义的相关报错,所以就会加上
inline关键词。编译器对内联的操作实际上就是将函数调用的那行代码用函数体进行替换,当然这个替换不是纯粹的复制粘贴,还会解决符号重定义的问题。
相当于宏,但比宏多了类型检查,真正具有函数特性
编译器一般不对包含循环、递归、switch等复杂操作的函数进行内联
在类声明中定义的函数,除了虚函数,其他函数都会自动隐式地当成内联函数
内联的非静态成员函数需要类内声明,类外定义
通过查看汇编代码可判断函数是否被内联
// 声明1(可加可不加inline,推荐加inline)
inline int functionName(int first, int second,...);
// 声明2
int functionName(int first, int second,...);
// 定义
inline int functionName(int first, int second,...) {
; // todo
}
// 类内定义,隐式内联
class A {
int doA() { return 0; }
}
// 类外定义,需要显式内联
class A {
int doA();
}
inline int A::doA() { return 0; } // 需要显式内联
Overload
让相同的函数根据不同的场景表现出不同的功能,提高复用性
触发函数重载的条件,函数名称相同,形参列表不一样,作用域一样(函数的返回值不作为函数重载的条件)
Parameter Pack
函数参数包(
parameter pack)需要配合模板使用
// typename|class ... pack-name(optional)
// Function parameter pack (a form of declarator, appears in a function parameter list of a variadic function template)
// pack-name ... pack-param-name(optional)
template<typename ... Tpack>
void fun(Tpack ...) {
}
int main() {
fun(1, 3, 5);
}
Data Structure
a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data
数据结构是数据值、数据关系、作用于数据的函数和操作的集合
Declaration and Definition
定义:定义是一种特殊的声明,使能实体被编译器使用
非定义性声明:告知编译器存在一个实体,等下可以使用它

ODR
一处定义原则:定义只允许在
翻译单元/程序单元出现一次需要满足
翻译单元级别的一处定义原则的包括:variable,function,class type,enumeration type,concept,template需要满足
程序单元级别的一处定义原则的包括:non-inline function,variable(违背这种规则的话,是未定义行为,看编译器自身的处理)一个程序中可以有多处定义的实体:
class type,enumeration type,inline function,inline variable,templated entity(仍需要满足某些前提)
ODR-use
一个对象说它,
ORD-used,当且其值被读写(除非其是编译期常量),被取址,被引用所绑定;一个引用说它,ORD-used,当且其引用对象是在运行期确定的;一个函数说它,ORD-used,当且其被调用或者被取址一个对象、引用、函数是
ORD-used时,程序中一定需要有定义,否则会有链接错误。
Header
尖括号:头文件在系统路径下找
引号:头文件先在用户目录下找,再在系统路径下找
Identifier
标识符是一段任意长序列,该序列由大小写拉丁字母,数字,下划线,和大部分Unicode字符组成
标识符能够给如下实体具名:
objects,references,functions,enumerators,types,class members,namespaces,templates,template specialization等
Literals
字面值示例:
// integer literal
211...
// string literal
"hello world"...
// boolean literal
true
false
// character literal
'a'...
// the pointer literal
nullptr
// the user-defined literal
...
// floating point literal
注意
注意 literals 和 literal type 是不一样的
Macro

Memory
Memory Layout
c++程序所占的内存可以划分为四个区域
代码区(text):存放函数体的二进制代码;由操作系统进行管理的;其中的内容是只读(防止修改程序的执行指令)和共享的(只有一份数据,避免拷贝浪费)全局区(data):存放全局变量、静态变量、字符串字面值常量;数据的生存周期由操作系统管理栈区:存放函数的参数值,局部变量;数据的生存周期由操作系统管理堆区:存放的数据的生存周期由程序员管理;若不释放,程序结束时由操作系统释放
Memory Leak
new返回的指针被释放,导致原来被指向的对象不能通过该指针来访问和不能使用delete来释放
New and Delete

auto ptr = new int (6);
auto ptr = new (int) {6};
// 构造数组
int *arr = new int[10];
// 构造数组,数据默认初始化为0
int *arr = new int[10]();
// 当分配失败时,不抛出异常,而只是
auto ptr = new(std::nothrow) int(4);
有没有数组的快速构建,不打这么长
vector
vector<vector<int>> dp(row, vector<int>(col)); // ok
new dp int[row][col]; // error
new dp int[row][2]; // ok,只有第一个的长度可以不用确定
int[row][col]; // error 如果row和col为局部变量则可以如此使用
int[row][2]; // ok
new对象数组时,只有第一位才能够是变量,其他都要是常量
auto p1 = new double[n][5]; // OK
auto p2 = new double[5][n]; // error: only the first dimension may be non-constant
跟
malloc一样new出来的内存空间不一定是内存对齐的(可以使用alignasspecifier)
struct alignas(256) Str{};
Str *ptr = new Str();
Malloc and Free
malloc和new的区别
Malloc/Free |
New/Delete |
|---|---|
堆区 |
栈区 |
函数 |
操作符 |
malloc只分配内存空间,不进行初始化(往内存空间中放数据)malloc不能保证分配的内存是对齐的,因此有aligned_alloc可以基于
allocator模板类分配内存空间和释放内存空间(一般用于维护内存池)malloc返回的是void*类型的指针,使用时需要自己进行类型转换
int *ptr = (int *) malloc(4 * sizeof(int));
Smart Pointer
引入智能指针是为了更好地管理指针和管理动态内存空间。以前管理动态内存是通过
new来分配内存空间,通过delete来释放内存空间。但容易发生一种情况,用new分配了内存空间,但是忘了使用delete释放内存空间,或者由于异常的抛出,程序无法调用delete,这就会造成内存的泄露(该释放的内存空间没有被释放)。于是就有人提出能不能有一种指针,在它销毁的时候,它所指向的对象也会被销毁,于是就引入了智能指针类,它包含了一个满足这种一并销毁需求的析构函数存在一种情况,一个对象由多个指针管理,那就可能会导致多次的释放,于是就引入了包含引用计数技术的共享指针
shared_ptr(每有一个共享指针,引用计数+1),只有引用计数为0时,指向的对象才会释放为了避免循环引用的情况,因此引入了弱指针。弱指针对其所指向的内存空间没有
所有权make_unique在c++14后才有提供,C++ 标准委员会主席Herb Sutter说有一部分原因是因为疏忽了(oversight)
#include <memory>
int main() {
std::shared_ptr<int> foo = std::make_shared<int>(10);
std::shared_ptr<int> foo2(new int(10)); // 实参为裸指针所指向的地址
std::unique_ptr<int> foo3 = std::make_unique<int>(10);
std::unique_ptr<int> foo4(new int(10));
return 0;
}
unique智能指针对象支持下标索引底层数据
#include <memory>
int main() {
auto arrA = std::make_unique<int[]> (10);
auto arrB = std::make_shared<int[]> (10);
arrA[0] = 1;
arrB[0] = 1;
return 0;
}
备注
注意类型带[]
提示
有的时候希望只能有一个智能指针管理对象,那就可以使用 unique_ptr
语法:
// 创建一个智能指针,该指针指向含10个整型数据的空间
auto pointer = std::make_shared<int>(10);
// ...,初值为0
auto pointer = std::make_shared<int>(10, 0);
拓展资料:csdn
Name
unqualified name:不在域解析符右边的名称
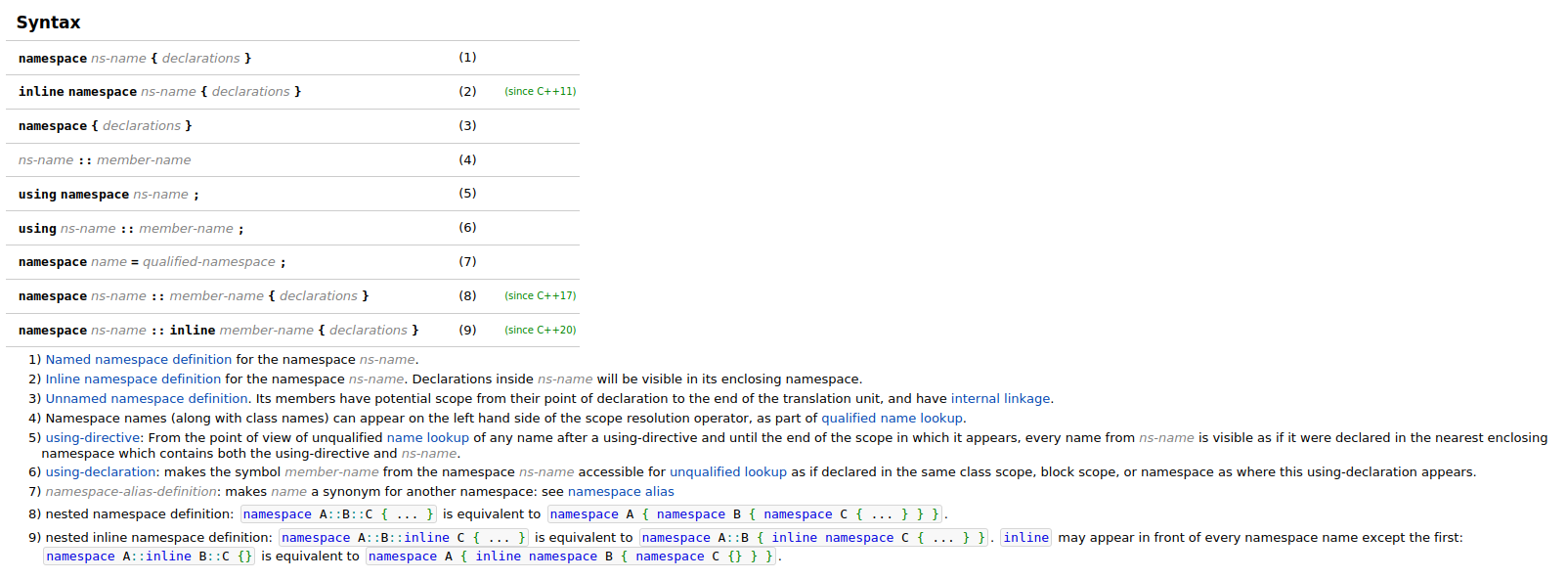
Namespace
Reference
引用不是对象,不占用
data storgaeconst左值引用和右值引用能够延展临时变量(或称不具名变量/匿名变量)的生存期;但是const左值引用
#include <iostream>
using namespace std;
int main() {
double tc = 21.5;
/*
* 以下近似于:创建一个临时变量,然后对其进行绑定
* double temp = 7.07;
* const double &rd1 = temp;
* 在语法上只有const左值引用才能绑定临时变量,否则有如下报错:
* “non-const lvalue reference to double can not bind a temporary of type double”
*/
const double &rd1 = 7.07;
// 通过const左值引用或右值引用对临时变量起别名,临时变量的lifetime会被extend
double &&rd2 = 7.07;
rd2 = 33;
}
Forward Reference
Reference Collapse
引用折叠只会发生在类型别名和模板
typedef int &lref;
typedef int &&rref;
int n;
lref &r1 = n; // type of r1 is int& 左值引用 + 左值引用 -> 左值引用
lref &&r2 = n; // type of r2 is int& 左值引用 + 右值引用 -> 右值引用
rref &r3 = n; // type of r3 is int& 右值引用 + 左值引用 -> 右值引用
rref &&r4 = 1; // type of r4 is int&& 右值引用 + 右值引用 -> 右值引用
Dangling Reference
当引用的对象的lifetime已经结束了,那此时的引用则为 dangling reference,相关的报错信息为段错误
std::string &f() {
std::string s = "Example";
return s; // exits the scope of s:
// its destructor is called and its storage deallocated
}
int main() {
std::string &r = f(); // dangling reference
std::cout << r; // undefined behavior: reads from a dangling reference
std::string s = f(); // undefined behavior: copy-initializes from a dangling reference
}
Q&A
a是T的左值引用,T是int&&类型的,那a实际上是什么(类型)?
A1:int&(根据引用折叠的说法,右值引用的左值引用是左值引用)
Type
类型(type)是函数(function)、表达式(expression)、对象(object)的属性;类型决定了二进制值的转译方式(这些二进制值可能存储在对象中,也可能是表达式求值(evaluation)后的结果)
#include <iostream>
int main() {
// 二进制1100001的int型表示为 -> 97
// 二进制1100001的char型表示为 -> 'a'
using namespace std;
int int_num = 97;
char char_num = int_num;
cout << "int_num: " << int_num << endl;
cout << "char_num: " << char_num << endl;
}
alignment requirement
alias
用简短的类型别名替换完整的、较长的类型名
// 语法一
typedef src_type alias_type
// 语法二(from c++11)
using alias_type = src_type
备注
一般来说,推荐使用 using 这种语法,因为在标识数组类型时, using 会更直观(如下例所示);另外[typedef不支持模板类别名](https://www.cnblogs.com/yutongqing/p/6794652.html)
int arr[4];
typedef int IntArr[4]; // [4]需要写在后面
using IntArr = int[4];
size_t
size_t类型是一个特殊的类型别名,是sizeof()函数的返回值类型其是一个无符号的整型,大小由操作系统所决定的;在进行动态内存分配时很有用。
注意
标准库中的`operator[]`涉及`size_t`,所以遍历时用`unsigned`或者`int`类型的数据去访问可能会出错

incomplete type
.... has initializer but incomplete type
incomplete type:这种类型的对象,编译器是不知道它的大小的,如int[]
aggregate
array
没有引用的数组。因为数组的元素应该是对象而引用不是对象。
Implict Conversion
编译器的隐式类型转换包含了一系列的尝试,依次为:标准类型转换集(standard conversion sequence),用户级别的类型转换集(user-defined conversion),标准类型转换集(standard conversion sequence)
Standard Conversion Sequence
步骤一:左值到右值的转换;数组到指针的转换(
array to pointer);函数到指针的转换(function to pointer)步骤二:数值提升(
numeric promotion)或数值转换步骤三:function pointer转换
步骤四:
CV修饰符转换(qualification conversion)
Array to pointer
数组类型的对象是一个左值(能被取地址),但不能被修改(即放在赋值操作符的坐标)
数组类型到指针类型的隐式转换(当上下文需要指针时,数组类型就会转为指针类型)(@ref)
int a[3];
// 该指针指向数组的首元素
auto b = a; // b->int* 而不是 int*[3]

Explicit Cast
C-style:c风格的显式类型转换包含了一系列的转换操作(也就是它会尝试一组转换操作,例如首先进行const_cast,然后进行static_cast,reinterpret_cast...);c++中一般都使用细颗粒度的,更具体的c++风格的类型转换操作(即static_cast,const_cast,reinterpret_cast等)

备注
建议通过程序的改良,来减小对类型转换的使用。(李伟老师:设计`static_cast`这些要打这么长而麻烦的函数,就是为了降低开发者使用类型转换的频率)
C++-style:
// 使用const-cast消除只读性和易变性
dynamic_cast:用于实现多态类型的转换(只适用于指针或引用),如将父类指针转换为子类指针。父类指针调用子类方法
// 非调用虚函数时需要使用dynamic_cast将父类指针转换为子类指针
dynamic_cast<cl::NetTensorRT *>(net_.get())
->paintPointCloud(*pointcloud_ros, color_pointcloud, labels.get());
reinterpret_cast:用另一种类型解读数据,比如二进制数据1100001用char类型解读为'a',用int型来解读则为97
Pointer
operator
int arr[4] = {1, 2, 3, 4};
int *ptr = arr;
// 等价于输出ptr[0]
cout << *ptr << endl;
// 等价于prt[3]
cout << *(ptr + 3) << endl;
往字节流中存储任意类型的数据
步骤一:reinterpreter_cast字节流到待存储数据的类型,然后存值
步骤二:将指针指向下一个位置
template <typename T> void write(char *&buffer, const T &val) {
// T buffer[] = val;
*reinterpret_cast<T *>(buffer) = val;
buffer += sizeof(T);
}
void serialize(void *buffer) {
char *d = static_cast<char *>(buffer);
int mClassCount = 3;
write(d, mClassCount);
}
Template
学习模板不是为了写模板,而是为了调用
STL的模板
template有三种参数:类型模板参数(
type template parameters),非类型模板参数(non-type template parameters),模板的模板参数(template template parameters)
Argument Deduction
要实例化一个模板,模板的每个形参都能有对应的模板实参。编译器要知道模板的实参,一是显式地指定,二是隐式地推导(相应的时机比如触发可函数调用),三是使用默认值。
Class Template
只有被调用的成员函数,才会被实例化(可以减少程序的大小,减少编译的时间)
类模板的显式和隐式实例化
template<class T>
struct Z // template definition
{
void f() {}
void g(); // never defined
};
// template class-key template-name <argument-list>;
template struct Z<double>; // 显式实例化: Z<double> 放在全局域
int main() { // template-name <argument-list> object_name;
Z<int> a; // 隐式实例化: Z<int>
Z<char> *p; // 该类型的实体没有被调用,只是创建了指针实体,不会触发模板的隐式实例化
p->f(); // implicit instantiation of Z<char> and Z<char>::f() occurs here.
// Z<char>::g() is never needed and never instantiated: it does not have to be defined
}
Function Member Template
成员函数模板的类外定义:(类内声明和类外定义的
一致性)
struct X {
template<class T> T good(T n);
template<class T> T bad(T n);
};
template<class T> struct identity { using type = T; };
// OK: equivalent declaration
template<class V>
V X::good(V n) { return n; }
// Error: not equivalent to any of the declarations inside X
template<class T>
T X::bad(typename identity<T>::type n) { return n; }
Constraint
20标准引入
constaint对模板进行约束Named sets of such requirements are called concepts.
Each concept is a predicate, evaluated at compile time, and becomes a part of the interface of a template where it is used as a constraint
对模板实参的约束称为
requirement,requirement的名字称为concept,
Concept
想要对模板参数进行相应的限制
// concept的定义语法
template <template-parameter-list>
concept concept-name = constraint-expression;
// concept
template<class T, class U>
concept Derived = std::is_base_of<U, T>::value;
Requires
requires表达式返回一个
bool值Simple requirements:不进行取值,编译器检验实参的某些操作是否合法
template<typename T>
concept Addable = requires(T a, T b)
{
// requires {requirement-seq}
a + b; // "the expression a+b is a valid expression that will compile"
};
Type requirements:检验类型实参是否为指定类型Compound requirements:检验实参是否满足某种操作,这种操作的返回值类型是否合法Nested requiements:含各种复合语句
Instantiated
触发显式地实例化(一个程序只能有一次触发),生成相应的代码(@ref)
类模板显式实例化定义
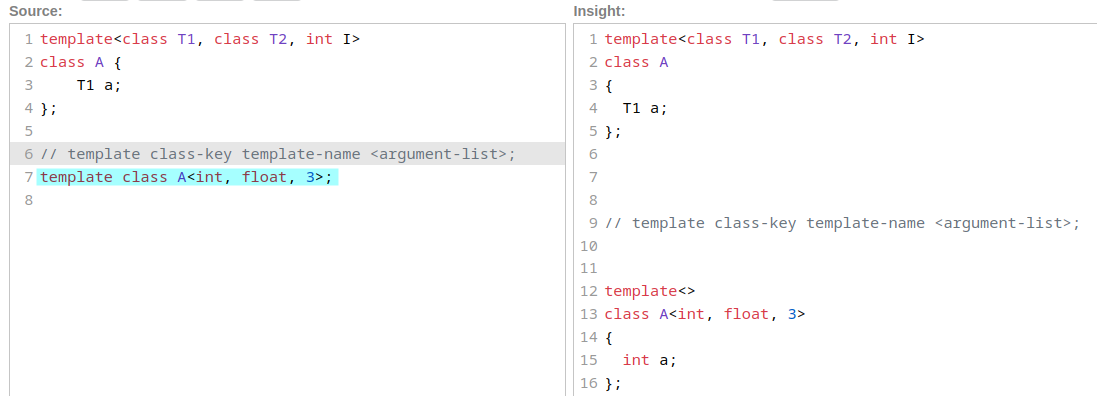
函数模板显式实例化
template return-type name <argument-list> (parameter-list); (1) // 不需要模板实参类型推导
template return-type name (parameter-list); (2) // 需要模板实参类型推导(根据函数形参)
template<typename T>
void f(T s)
{
std::cout << s << '\n';
}
template void f<double>(double); // instantiates f<double>(double)
template void f<>(char); // instantiates f<char>(char), template argument deduced
template void f(int); // instantiates f<int>(int), template argument deduced
// 当前翻译单元不进行实例化,使用其他翻译单元提供的实例化
extern template class-key template-name <argument-list>;
Specialization
编译器根据模板生成函数/类定义(definition)的行为称为模板实例化(template instantiation)。其中生成的definition称为特化(specialization);一个被特化的模板称为primary template
Explicit template specialization
显式的模板特化,也称为全特化
自定义模板代码
语法
template <> declaration
示例
#include <iostream>
template<typename T> // primary template
struct is_void : std::false_type {};
template<> // explicit specialization for T = void
struct is_void<void> : std::true_type {};
int main()
{
// 模板实参为void之外的类型,则继承false_type
std::cout << is_void<char>::value << '\n';
// 模板实参为void时,则继承true_type
std::cout << is_void<void>::value << '\n';
}
Partial Template Specialization
仅适用于类模板和变量模板
特化的实参限制
Perfect forward
基于引用折叠和std::forward函数便能实现完美转发(即一个函数能够保证实参的value category保持一致地转发)
Compiler
链接阶段,不同翻译单元相同的实例模板(
instantiations)将被合并
Q&A
写一个既能接收左值又能接收右值的函数模板
template<class T>
void fun(T &¶m) {
return g(std::forward<T>(param));
}
Object
(定义)An object, in C, is region of data storage in the execution environment, the contents of which can represent values (a value is the meaning of the contents of an object, when interpreted as having a specific type). @ref
Object的分类(complete / subobject / polymorphic)可参考 @ref
一个Object具有各种属性:size;alignment requirement;storage duration (对应内存的生存周期);lifetime;type;value;optionally, a name.
Polymorphic Objects
类类型的对象如果声明或继承了一个虚函数,那就是多态对象。每个多态对象都会被隐式添加一个虚函数指针,然后被用于虚函数调用;非多态对象所在的表达式,其取值evaluation是在编译期决定的
Q&A
lifetime和storage duration的概念是否相同?
两者是不同的概念,局部变量的storage duration为,块域的开始和结束;其lifetime的开始为初始化完成,结束为相关的内存被释放。总的,有如下观点,分配了内存,对象的生存期不一定开始。
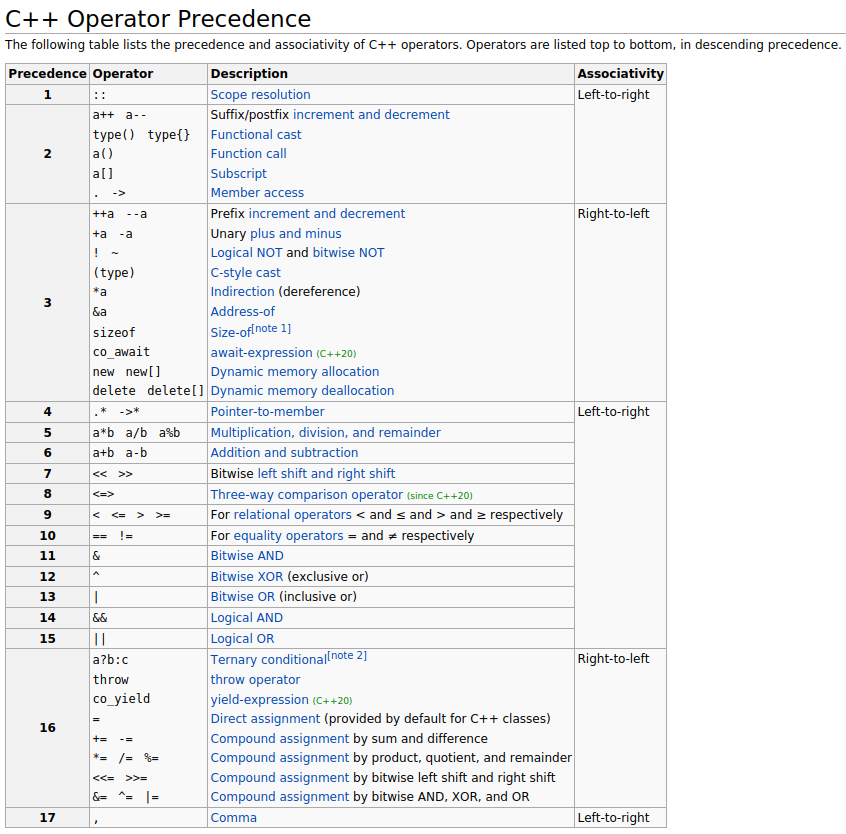
Operator
操作数需要满足操作符的类型需求,左值/右值类型需求
3 = 5; // error 赋值语句左边需要是左值
new和delete这些也是操作符,因此可以重载
Precedence
void fun(int p1, int p2) {}
int main() {
int x = 0;
fun(x = x + 1, x = x + 1); // undefined behaviour(是为了支持乱序执行),可能先执行左边,也有可能执行右边(看编译器实现)
}
Add
一元加法操作符能触发整型提升(
integral promotion)

Logical
其操作数和结果均为右值(结果的类型为bool)
Increment
后缀表达式(i++)的优先级高于前缀表达式(++i)
后缀表达式的取值(evaluation)为
右值(返回是操作数的拷贝/临时变量);前缀表达式的取值为左值(在原来的值的基础上+1)一般推荐使用前缀表达式,避免拷贝的开销;但现在一些编译器已经能够对后缀表达式进行优化,使其不用构建临时变量
Post-increment and post-decrement creates a copy of the object, increments or decrements the value of the object and returns the copy from before the increment or decrement.
int main() {
int arr[] = {1, 2, 3};
auto ptr = arr;
cout << *ptr << endl; // 1
cout << *ptr++ << endl; // 1 后缀表达式的evaluation为原值的copy;此处等价于*(ptr++)->*ptr
cout << *++ptr << endl; // 3 后缀表达式处理完后,地址已+1,此处地址再+1;此处等价于*(++ptr)
}
Comma
虽然左操作数也要进行取值(evaluate),但逗号操作符表达式的取值(evaluation)只跟第二个操作数的取值有关(它们的type, value, value category将保持一致)

Scope resolution
全局作用域符(
::name)用于类、类成员、成员函数、变量前,表示作用域为全局命名空间类作用域符(
class::name):用于表示指定类型的作用域范围是具体某个类的命名空间作用域符(
namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
Operator Overload
操作符实际上是一种特殊的函数,比如以下就等价于调用
operator.+这个函数
std::string str = "Hello, ";
str.operator+=("world"); // same as str += "world";
重载的操作符的参数个数取决于操作符本身,形参的类型至少有一个是类类型
除
operator()外其他运算符都不能使用默认参数操作符支持两种方式的重载,一种是作为成员函数,一种是作为非成员函数。(
=,[],->,()都是需要作为成员函数进行重载)对于输入输出流的操作符,不能作为成员函数进行重载,因为操作符的左操作数应该为输入/输出流对象
逻辑运算符的重载会丢失短路逻辑
实例:加法运算符作为成员函数的重载
class Str {
public:
int val = 2;
Str &operator+(const Str &str) {
this->val += str.val;
return *this;
}
};
using namespace std;
int main() {
Str str1;
Str str2;
str1 = str1 + str2;
cout << str1.val << endl;
}
Initialization
初始化即给对象提供初值;函数调用和函数返回时也存在初始化;
初始化器(
initializer)有三种:含花括号,含圆括号(initializer list) ,含等号
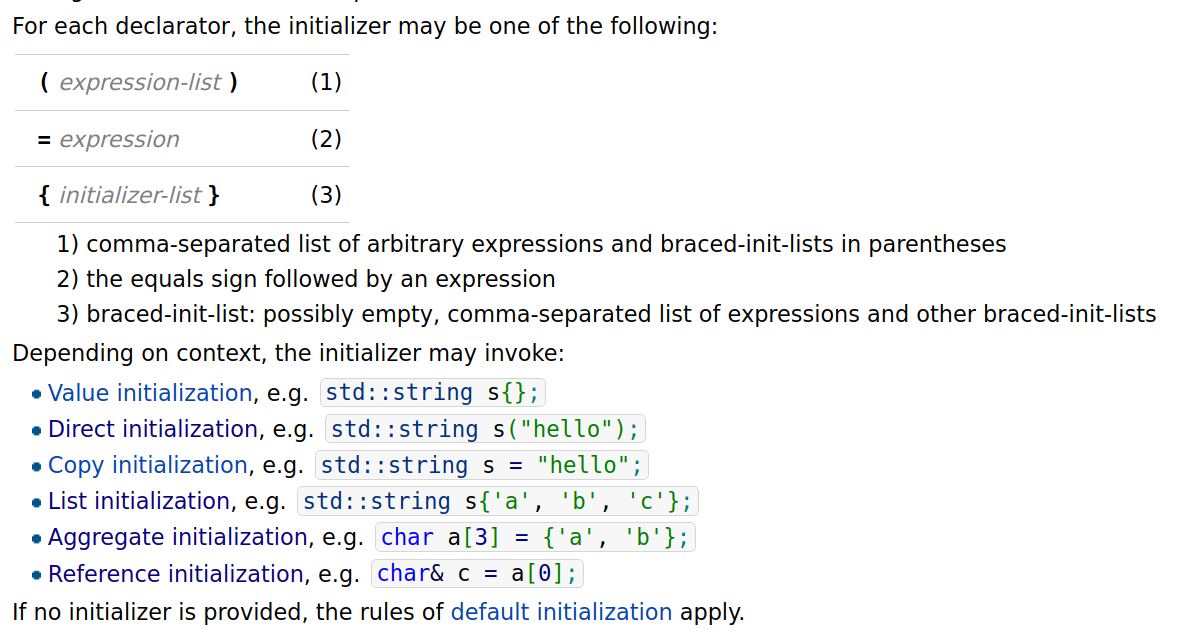
开辟内存空间时会构造符号表,将标识符和相关内存空间关联起来(至此,如果要用到一个变量名为a的变量时,就知道在内存的哪个地方找到这个变量)
Copy Initialization

Pragma once
#pragma和#ifdef/#ifndef/#endif一样都是preposess directive(预处理指令),前者是编译器特性(部分版本较老的编译器不支持),后者是c++标准(所有编译器都支持该语法);都能保证一个头文件不会被重复包含(include)。前者的作用单位是一个文件,后者的作用单位是代码块。前者对于某些编译器能够提高编译速度;后者需要避免有重复的宏名。
Signature
Syntactic sugar
Range-based for Loop
又称为range-for,是for循环的语法糖(编译器会转换为for循环的调用方式),用于遍历序列容器、字符串和内置数组
(规范)使用常量左值引用读元素,使用万能引用修改元素。因为迭代的元素可能是临时变量(比如
vector<bool>的返回值是临时变量)
Structured Binding
为c++17的特性,类似python的解包;structured binding是一个已存在对象的别名(alias),类似引用,但又有区别
Qualifier
const
const用于描述对象的可读性(注意只用于修饰对象)常被修饰的实体
实体 |
作用 |
|---|---|
普通对象 |
该对象是只读的,尝试修改会报编译期错误 |
指针 |
常指针,该指针的指向不发生变化 |
类对象 |
该对象只能调用 |
类成员函数 |
该对象的 |
示例
// 类
class A
{
private:
const int a; // 常数据成员,只能在初始化列表赋值
public:
// 构造函数
A() : a(0) { };
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数,该函数不得修改类中的任何数据成员的值
};
void function()
{
// 对象
A b; // 普通对象,可以调用全部成员函数、更新常成员变量
const A a; // 常对象,只能调用常成员函数
const A *p = &a; // 指针变量,指向常对象
const A &q = a; // 指向常对象的引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指向常量的指针
char* const p3 = greeting; // 常指针(指针的指向不能发生改变)
const char* const p4 = greeting; // 指向常量的常指针
}
// 函数
void function1(const int Var); // 形参只读
void function2(const char* Var); // 形参为指针,指向的对象只读
void function3(char* const Var); // 形参为指针,指针为常指针
void function4(const int& Var); // 常量的引用
// 函数返回值
const int function5(); // 返回一个常数
const int* function6(); // 返回一个指针,指针指向常量
int* const function7(); // 返回一个常指针
``const`在*后修饰的是指针;
const在*前修饰的是指向的对象 <https://en.cppreference.com/w/cpp/language/pointer>`_
// 指向数组的指针(int (*)[n]) vs 指针数组(int *[n])
data type (*var name)[size of array];
int (*ptr)[5] = NULL;
int* var_name[array_size];
// 指针p只读
int* const p;
// 不能修改指针p所指向的对象
const int* p;
int const* p;
顶层
top-level const和底层low-level const(@ref)
一般说到顶层const和底层const,对应的场景是说const修饰的是指针还是指针指向的对象,如果是顶层const的话,则修饰的是指针(对应的是指针常量),如果是底层的话,则const修饰的是指针指向的对象(对应的是常量指针)
volatile
让一个对象避免对编译器优化,使得每次读写该对象时,都需要从内存中访问
Specifier
constexpr
constexpr修饰对象时,可以等价于const,表示其为只读的;相比于const,constexpr还能用于修饰函数,表明这些函数和变量的值可能能在编译期确定(evaluation),可以放在constant expression中能在编译期进行evaluation的表达式称为constant expression
explicit
告知编译器某个构造函数或者类型转换函数只能被显式调用,而不能进行隐式类型转换和拷贝初始化
noexcept
指示编译器该函数不会抛出异常,可进一步进行优化(减少引入栈展开的逻辑)

被重写函数的异常处理逻辑可以更加简单,但不能反过来,比如说基类引入了栈展开的逻辑(即会处理异常),派生类就可以移除栈展开的逻辑(即用
noexception修饰函数)
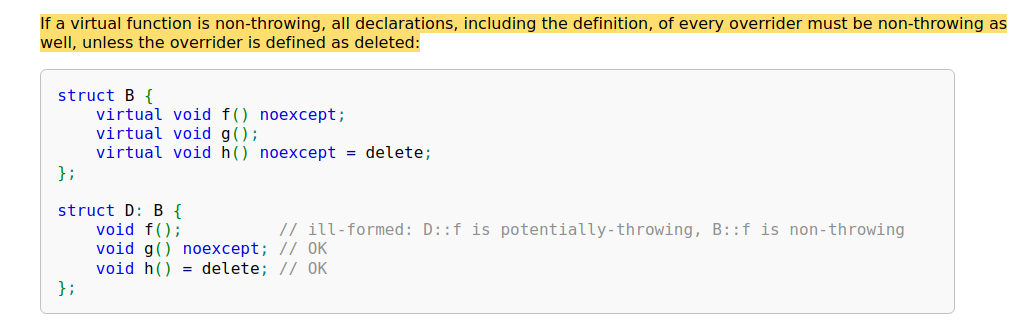
override
让编译器检查这个函数是否是虚函数,而且是否经过重写(override)
final
修饰类成员函数:指示这个成员函数是虚函数且不能再被重写,让编译器进行检查
修饰类:指示这个类不能被继承,让编译器进行检查
static
根据不同的对象,表现出不同的作用
修饰普通变量,修改变量的存储区域和生命周期(lifetime),使变量存储在静态区,在main函数运行前就分配了空间
修饰普通函数(描述该函数具有内部链接性)。在多人开发项目中,为了防止与他人命名空间里的函数重名,可以将函数定位为
static修饰成员变量(相当于声明类属性):所有对象能共享同一份数据;在编译阶段分配内存;其是类内声明,类外定义(语法);访问时可通过对象或类名进行访问;也可以有访问权限
修饰成员函数(相当于声明类方法):所有对象共享同一个函数;该方法不能访问实例属性;类内声明,类外定义;访问时可通过对象或类名进行访问;也可以有访问权限
静态成员
在类定义中,
static用于声明一个静态成员(类属性或者类方法)通常是放在其他
specifier前面,但具体位置实际上没硬性要求一般的静态数据成员需要是类外定义;而内联的静态数据成员能够在类内初始化(C++17)
常数据成员可以类内定义(初始化器需要是常量表达式)
virtual
声明一个函数能被派生类重写
virtual不能修饰静态成员函数(虚函数需要this指针,而静态成员函数没有this指针)
Variable
被声明的对象和引用如果不是非静态数据成员则他们为变量
Feature
Polymorphism
多态是C++的一种特性。多态即让一个对象或一个函数在不同场景下表现出不同的行为和逻辑。比如说对于加法运算,它的操作数是数字的话,那他表现出来的逻辑就是数学运算,如果操作数是字符串的话,那他表现出来的逻辑就是字符串拼接。C++通过重载(overload)和重写(override)实现多态。其中基于重载的多态称为静态多态,基于重写的多态称为动态多态。clio