PythonPractice
exec vs setattr (time)
import time
class A:
def __init__(self):
self.value = 1
self.vdict = {}
self.vdict['0'] = str("self.value")
start = time.time()
for i in range(1000):
setattr(self, self.vdict['0'], 5)
print('TIME(ms) is=', 1000 * (time.time() - start))
start = time.time()
for i in range(1000):
exec(self.vdict['0'])
print('TIME(ms) is=', 1000 * (time.time() - start))
if __name__ == '__main__':
classA = A()
进程与线程
为什么pyqt不会因为键盘中断而停止?
正在执行C字节码,而没法执行中断
当触发一个键盘中断(-s 2)时,python会捕获到这个信号,并给全局变量置位(例如:
CTRL_C_PRESSED = True; 当python解释器执行一个新的python字节码而看到该全局变量设置时,则会抛出一个KeybordInterrupt;背地里的意思是,如果python解释器在执行C拓展库的字节码时(例如QApplication::exec()),触发ctrl+c则不会中断当前的程序,除非触发了python写的槽函数。
信号回调函数只能在主线程处理

python的 信号回调函数 的定义和执行只能在主线程中。若有主线程main和子线程A,则即使子线程收到了信号,也只会在主线程中执行。凡此,python的信号机制不能用于线程间通信。
自定义信号中断函数
import signal
def keyboard_interrupt_handler(signal, frame):
pass
signal.signal(signal.SIGINT, keyboard_interrupt_handler)
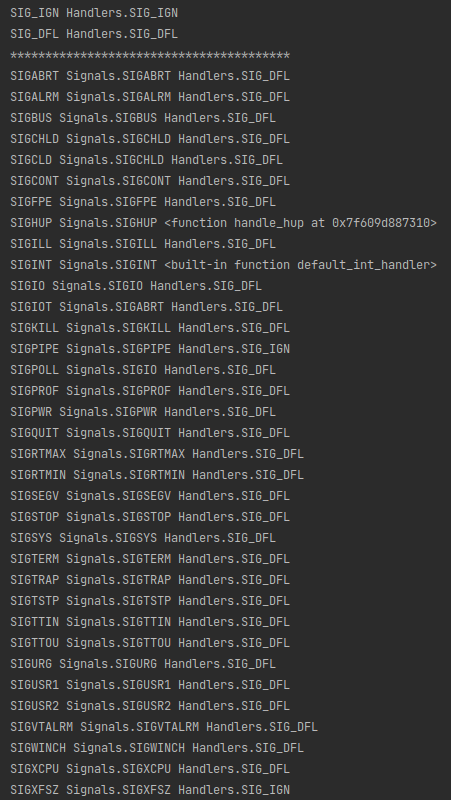
信号的默认处理机制
竞态
以线程为例,竞态 可以分为两种情况,一个是 线程并行 情况下的竞态;一种是 线程并发 情况下的竞态。线程并行的情况下,多个线程对同一个资源同时的访问,而导致资源被污染(python由于GIL,一般不存在这种情况);而线程并发的情况下即,多个线程并发地使用了某个资源而导致资源没有得到预期的结果。这种情况,比如 线程A 和 线程B 都需要对 变量V 加+1,理论上最后得到的结果是V+2。但存在一种情况,当 线程A 读取完 变量V 而还没来得及对 变量V 赋值时,由于系统调度而切换到 线程B 来对 变量V 进行赋值,此时变量V为V+1;接下来由于系统调度又切换回线程A,此时线程A的值是用它上一次读到的值进行+1操作,而不是用最新的值进行+1操作,所以最终得到的结果是V+1,而没有得到预期的结果。为了避免数据被污损的情况,可以使用 互斥锁 来避免资源被多个线程访问。
可以给线程A上锁,只有锁被release了,线程B才能使用使用变量V,这种情况下线程B就会处于阻塞的状态(阻塞是一种实现),如果with的那一部分需要执行很长的时间,那线程2就基本就game over了(线程的并发就成了线程的串行)
锁
from threading import Lock
lock = Lock()
# 线程1:
with lock:
# todo fun(variableA)
# 线程2:
with lock:
# todo fun(variableB)
需要访问同一资源的线程都需要上锁
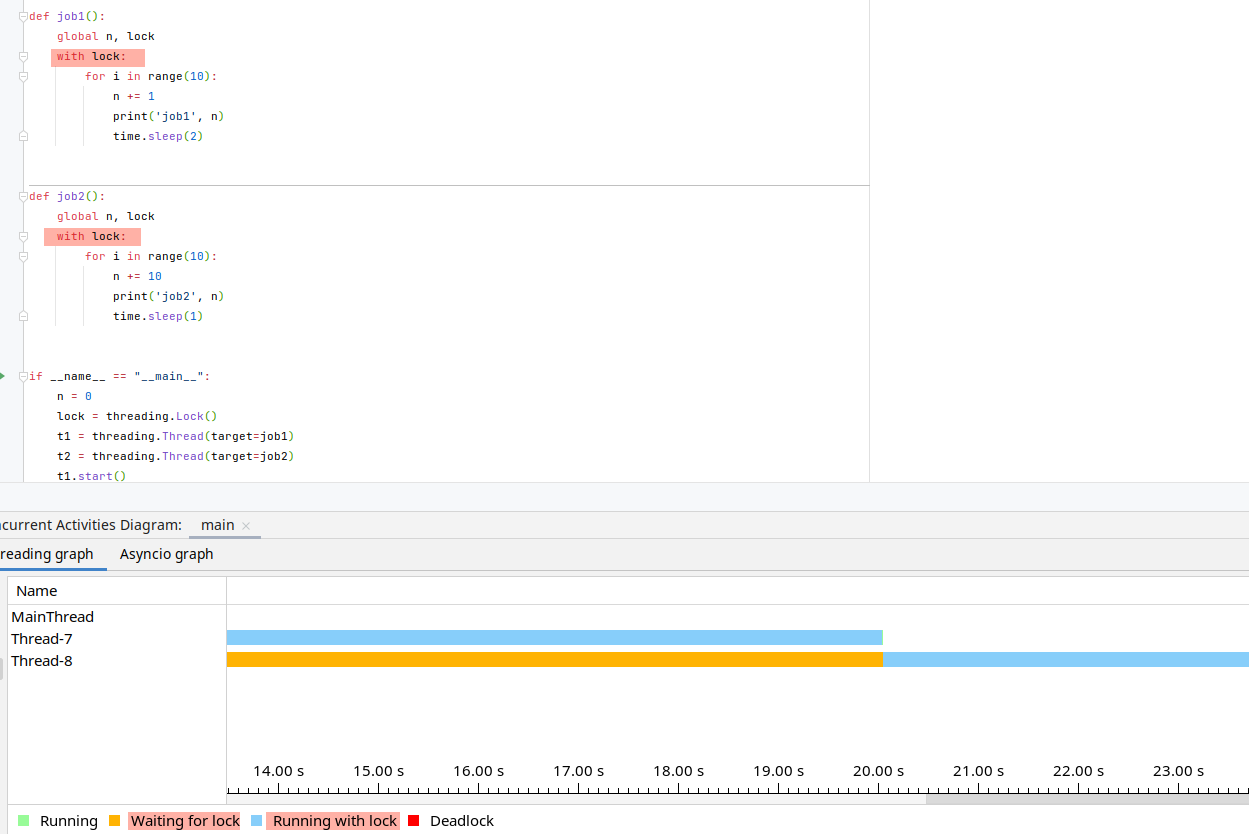
否则达不到预期的效果:

构建配置文件
在大型深度学习模型中,通常需要使用配置文件存储参数
方法一:基于python构建,内部存储字典数据,然后到时import python文件(参考livox_detection)
# config/config.py
CLASSES = ['car', 'bus', 'truck', 'pedestrian', 'bimo']
# 另一文件用于调用该配置
import config.config as cfg
方法二:基于yaml存放配置参数,然后调用内置库读取(参考OpenPCDet)
DATASET: 'KittiDataset'
DATA_PATH: '../data/kitti'
python中的路径问题
在windows中读取文件可以使用"",但在字符串里面""会被当成转义字符,所以要在字符串前加"r"避免转义。windows下的路径也可以使用"/"
# e.g.
"C:/Users/Administrator/Desktop"
字符串处理
常见操作
# 默认去开头/结尾的空格和换行符 \n
<str>.strip()
# 以某个符号为分界点进行分割(不包含该符号);默认分割符为空格和换行符
<str>.split()
格式化处理
格式化 |
描述 |
|---|---|
%s |
字符串 |
%10s |
右对齐,占位符10位(空格补齐) |
%.2s |
只保留两位的字符串 |
%10.2s |
10位字符串,只保留两位的字符串 |
r"str" |
不对字符串进行转义操作 |
u"str" |
以Unicode格式进行编码 |
num = 100
print(f"{num:0>4d}") # 0100
实例
读取文件P2字段的标定数据
# 去头去尾(去\n等回车符)-> 以空格为分隔符进行分割 -> 去除'P2:'字符串 -> 类型转换(str->num) -> reshape 得到变换矩阵
np.array(lines[2].strip().split(' ')[1:], dtype=np.float32).reshape(3, 4)

深拷贝和浅拷贝
# 浅拷贝:外层对象地址改变,内层对象地址不改变
copy.copy()
# 深拷贝:内外层对象地址均改变
copy.deepcopy()
语法
内置变量
字典
用B字典的键值更新A字典的键值
A = {"a": 1, "b": 2}
B = {"a": 3, "b": 3, "c": 4}
A.update(B)
print(A) # {'a': 3, 'b': 3, 'c': 4}
列表
# 列表翻转
A = [1,4,5,7]
A_rev = list(reversed(A)) # list(迭代器)
# 列表移除某个值(只能移除第一个出现的值)
A.remove(<list>)
A.append(B) # 将列表B以元素的形式加入到列表A中
A.extend(B) # 列表B的元素加入到列表B中
集合
# 交集
A & B
匿名函数
add = lambda x,y:x + y
add(4,3)
继承
子类不重写init方法,则实例化时自动调用父类的init方法;子类重写init方法后,又想调用父类的init则需要
# 等价于:父类名称.__init__(self, 参数1, 参数2,...)
super(子类,self).__init__(参数1, 参数2, ...)
多继承时,如果子类没有重写init,实例时自动调用的是第一个类的init方法
for else
迭代完成后执行else后的语句
实战
判断一个数(浮点数)是否是整数
# 方法一:
(num).is_integer
# 方法二:
num % 1 == 0
编码转换
str和byte的转换
# byte -> str
<byte>.decode()
# str -> byte
<str>.encode()
img和base64的转换
# img转为base64
with open("img_path", 'rb') as f:
# 将图片编码成base64 string数据,
b64str = base64.b64encode(f.read()).decode()
指定脚本运行的解释器
相对路径(取决于当前的虚拟环境)
/usr/bin/env python
绝对路径
/usr/bin/python2.7
该解释器配置可以被命令行指定的python覆盖