File
Author: kuzen, Natsu-Akatsuki
Open Directory
xdg-open
Switch Dircetory
jump
一般都是跳转到使用次数最多的文件夹
安装(for ubuntu)
wget https://github.com/gsamokovarov/jump/releases/download/v0.40.0/jump_0.40.0_amd64.deb && sudo dpkg -i jump_0.40.0_amd64.deb
echo 'eval "$(jump shell)"' >> ~/.bashrc
Find File
locate
sudo apt install mlocate
更新数据库
sudo updatedb
locate <文件名>
find
find [-H] [-L] [-P] [-Olevel] [-D debugopts] [path...] [expression]
-name: file name
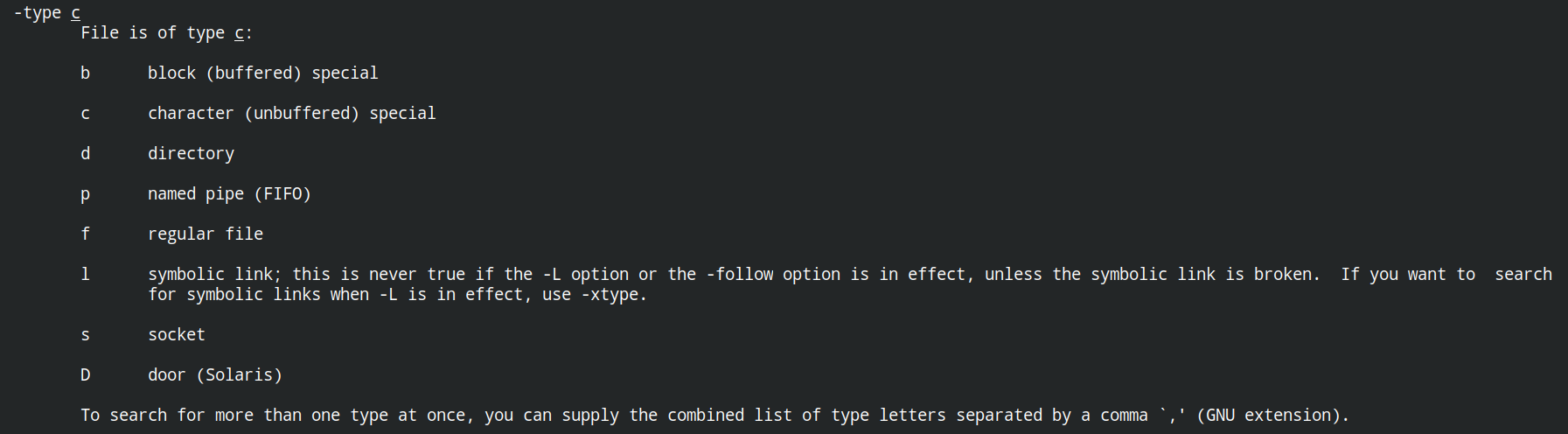
文件类型:
du
统计当前目录的文件夹大小
du -h --max-depth=1
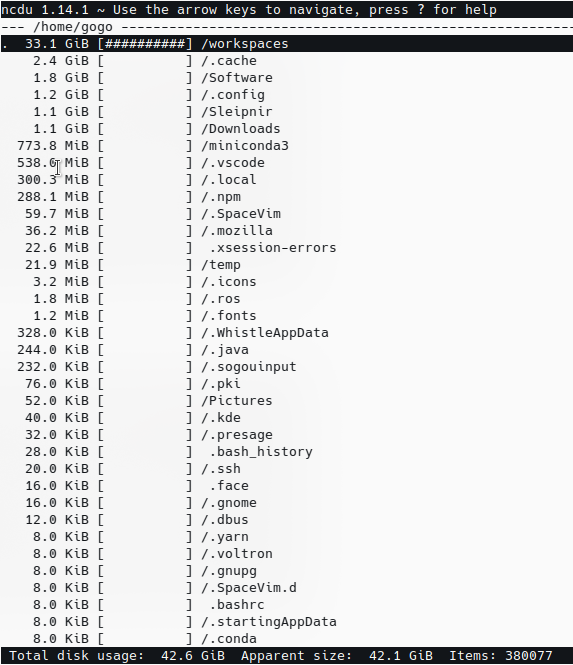
ncdu
效果同du,但可视化效果更友好和计算速度更快
sudo apt install ncdu
ncdu
View File
more
运行时可用按键
space:向下翻页
enter:向下翻行
/ :向下查找
:f :显示文件名和目前显示的行数
batcat
相当于带语法高亮的cat
安装
sudo apt install catbat
配置
echo 'alias bat="batcat --paging=auto"' >> ~/.bashrc
echo "export MANPAGER=\"/bin/bash -c 'col -bx | batcat -l man -p'\"" >> ~/.bashrc
REMARK
给man手册上色的功能很赞,但不建议使用(其不像man一样独享一个窗口,会跟前面的终端输出混在一起),可以使用most
Help Docs
help
多用于查看可用选项和参数、子命令
<命令行> --help
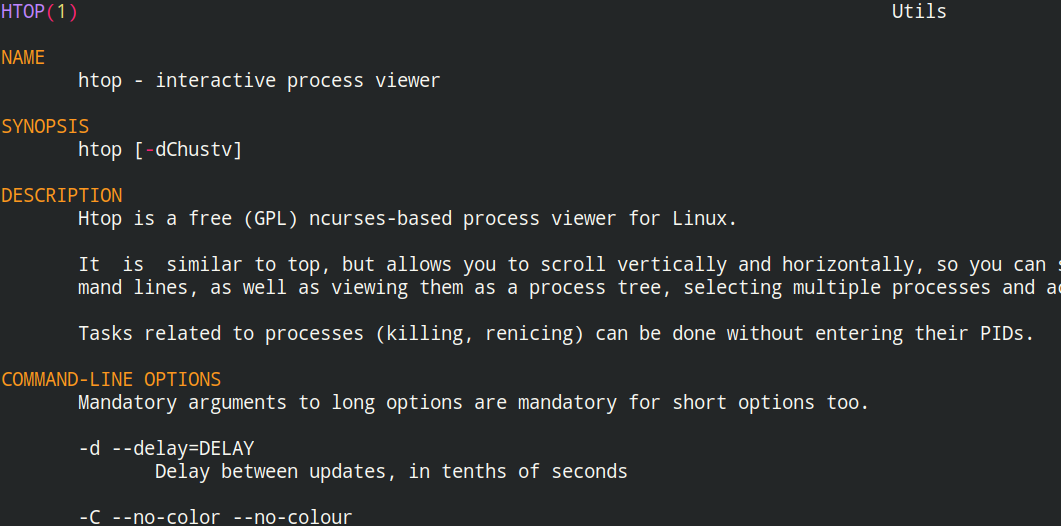
man
多用于查看详细的说明文档
man <命令行>
man面板页的可用操作
---跳转---
空格:向下翻一页
page down:向下翻一页
page up:向上翻一页
home:跳转到首页
end:跳转后尾页
---查找---
/string (enter):向下查找 n/N:向下查找/向上查找
?string (enter):向上查找 n/N:向上查找/向下查找
Archive
tar
压缩
tar -czvf <生成的压缩文件名> <待压缩的文件/文件夹>
解压缩
tar -xzvf <解压的文件名> -C <待存放的文件夹路径>
option |
效果 |
|---|---|
-C |
指定解压缩的目的文件夹 |
-c |
create a archive |
-f |
指定生成的压缩文件名/待解压的文件名 |
-v |
list verbose information |
-x |
解压 |
-z |
使用gzip的支持进行压缩 |
pigz
多线程解压缩
安装
sudo apt install pigz
压缩
tar -cvf - <待压缩的文件> | pigz -p 8 > <输出的压缩文件名>
-p:设置线程数
解压缩(分两步)p
unpigz <待解压的文件名>
tar -xf <待第二次解压的文件名.tar>
注意
注意命令行中有一个 >
zip
将split archive合成为一个压缩包
e.g
data_object_image_2.zip data_object_image_2.z01 data_object_image_2.z02 -> single.zip
zip -s 0 data_object_image_2.zip --out single.zip
unzip single.zip
解决解压后中文文件名乱码问题
unzip -O CP936 <待解压文件>
pv
显示解或压缩时的进度条
压缩文件
tar -cf - <待压缩文件或目录> | pv | gzip > <file.tar.gz>
解压缩
pv <file.tar.gz> | tar -xzf -
rar
sudo apt install unrar
解压缩
unrar x <file.rar>
Link
文件软链接
ln -s <源地址> <目的地>
可以不指定目的地,然后生成软链接到当前目录
ln -s <源地址>
注意
所有地址都需要绝对路径(实际使用时常跟 $(pwd) 配合使用)
管理文件软链接
e.g. manage gcc/g++
sudo apt install gcc-9 g++-9 gcc-10 g++-10
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 100 --slave /usr/bin/g++ g++ /usr/bin/g++-10 --slave /usr/bin/gcov gcov /usr/bin/gcov-10
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-9
其他常用选项
--remove-all name: Remove all alternatives and all of their associated slave links. name # is a name in the alternatives directory.
修改默认版本
sudo update-alternatives --config gcc

备注
指定slave和master的作用在于,master进行变动时,slave也会进行变动。比如gcc(master)从9.0切换到10.0时,g++(slave)也会从9.0切换到10.0
Edit File
vim
常用快捷键
命令行模式(Normal Mode)
作用 |
快捷键 |
|---|---|
(navigation) 向右移动一格 |
space |
(navigation) 向某个方向挪动n格 |
[n]<上向左右快捷键> |
(navigation word-based) 向右/向左跳转 |
w/b | ctrl+left arrow/ctrl+right arrow |
(cut and paste) 复制当前行 |
yy(yank) |
(cut and paste) 复制光标所在处到行首/行尾 |
y0/y$ |
(edit) 缩进 |
>> / << |
(edit) 撤销 |
u (undo) |
(edit) 反撤销 |
ctrl+r |
(区块选择)字符选择,给光标经过的地方高亮显色 |
v |
(区块选择)以矩形的方式选择数据 |
ctrl+v |
(区块选择)复制/删除/粘贴反白的地方 |
y/d/p |
末行模式
作用 |
命令行 |
|---|---|
删除指定行 |
:num, [num]d |
执行bash命令 |
:! |
向上查找 |
? |
向下查找 |
/ |
替换某些行[n,m]的某些词 |
:n,ms/待替换的词/被替换的内容/g |
替换前还要有交互(认证是否进行替换,末尾加c) |
:n,ms/待替换的词/被替换的内容/gc |
常用命令行
作用 |
命令行 |
|---|---|
删除全文 |
gg 然后再 dG(删除光标行及其以下行的全部内容) |
配置文档
共享系统的剪切板与vim的剪切板(鼠标中键、p、 c+s+v )
安装gvim插件,并在配置文档中添加:
set clipboard=unnamedplus:s
vim的全局参数配置文件放在
/etc/vim/vimrc但不建议修改,而是建议修改~/.vimrc
高级封装
spacevim 使用文档涉及,基本的配置文档设置、插件的更新
spacevim下的常用快捷键:
作用 |
快捷键 |
|---|---|
创建文件树面板 |
F3 |
拓展插件
备注
vim可打开pcd文件和rosbag等文件,以快速查看文件头
去重行
uniq
-i:忽略大小写
-c:进行计数
案例:统计账号登录次数
last | cut -d ' ' -f1 | sort | uniq -c
排序
sort
-f: 忽略大小写
-b:忽略前导空格字符,ignore leading blanks
-t:分隔符号
-n:利用数字排序
-k:用第几个字段进行排序
案例:对/etc/passwd的内容以账号id进行排序
cat /etc/passwd | sort -t ':' -k 3 -n
diff
记录文件改变的内容/不同的地方
diff A B
patch
根据文件的不同还原文件
patch - apply a diff file to an original
patch [options] [originalfile [patchfile]]
e.g. patch -pnum patchfile
Replace
sed
语法
sed [OPTION] {script-only-if-no-other-script} [input-file]...
{script-only-if-no-other-script}
s/<正则表达式(待替换的内容)>/<替换的内容>/:使用正则表达式进行替换
注意
替换部分有单引号;如果有特殊符号时则需要使用转义符号
实例
替换code-block为prompt-block
m2r ${file} && sed -i -e 's/.. prompt:: bash $,# auto/.. prompt:: bash $,# auto/' ${fileDirname}/${fileBasenameNoExtension}.rst
替换code-block为prompt-block
去掉行首的第一个$ prompt
m2r ${file}&& sed -i -e 's/.. prompt:: bash $,# auto/.. prompt:: bash $/' -e 's/$ //' ${fileDirname}/${fileBasenameNoExtension}.rst
更多可参考此网站(linux hint)
NOTE
s加g和不加g的区别:

常用选项
option |
效果 |
|---|---|
-i |
原地替换 (in-place replacement) |
-e |
command的拼接 |
perf
perf
option:
-i: edit files in place
-e: 后接command
perl -i -ep "s/unstable/$(lsb_release -cs)/" changelog
tee
tee /etc/apt/sources.list > /dev/null << EOF
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
EOF \
备注
传统和原始的Docker build不支持这种写法。它是逐行解析的。所以要不使用echo,要不使用新的解析方式 here_document
Extract
awk
逐行的字段分割(类型于python的str.split操作,默认分隔符为空格或Tab键)
awk '条件类型1{操作1} 条件类型2{操作2} ...' 文件名
查看/etc/passwd中第三字段小于10的数据,并且仅列出第一和第三字段
cat /etc/passwd | awk 'BEGIN {FS=":"} $3<10 {print $1 "\t" $3}'
BEGIN 表示条件类型的效果从首行开始生效(否则是从第二行才开始生效)
FS=":" 指定分割符(FS:内置变量)
注意
注意使用的是单引号
cut
以字符为单位,截取字符
cut -c 2-3 截取第二到第三个字符
cut -c 1- 截取第一个之后的字符(含第一个)
grep
grep [OPTION]... PATTERNS [FILE/DIR]...
<...> | grep -A 3 "..." # 附带输出结果的后三行数据
<...> | grep -B 3 "..." # 附带输出结果的前三行数据
<...> | grep -C 3 "..." # 附带输出结果的前后三行数据
递归查找某文件夹下含有该字符串的文件
grep -rn <pattern> <file>
去注释行和空格行
cat <file_name> | grep -v ^# | grep -v ^$
选项:
-o, --only-matching:只显示匹配的部分(一个匹配一行),不显示匹配行
-i:忽略大小写(ignore case distinctions)
-n:显示行数
-r:递归查找
-v:反选
--include:文件名需要满足的条件 --include "*.cpp"
xargs
读取标准输入作为某个命令的参数
xarg [option] cmd
案例一:
echo '--help' | xargs cat
等价于 echo cat --help
案例二:
xargs rm < install_manifest.txt
-a <file_name> 以文件的内容为标准输入
-i cmd {} 用{}指代标准输入
获取文件信息
dirname <absolute_file_name>
basename <absolute_file_name>
-s <extension> 去后缀
统计new line个数≈行数
wc -
Diff
sudo apt install meld
拓展
正则表达式
正则表达式是一个字符串匹配模板(pattern),可进行字符查找和信息提取;支持正则表达式的命令行包括,vim, locate, find, sed, awk, grep
语法
postion match
pattern |
function |
|---|---|
^char |
匹配处在行首的char字符 |
char$ |
匹配处在行末为char字符 |
word-level match
pattern |
function |
|---|---|
. |
匹配任意一个字符(除换行符n外),可匹配中文 |
[...] |
匹配在字符集中的字符 |
[^...] |
匹配不在字符集中的字符 |
d |
匹配数字 |
D |
匹配非数字 |
s |
匹配空白字符 |
S |
匹配非空白字符 |
w |
匹配英文、数字、下划线、中文字符 |
string-level match
pattern |
function |
|---|---|
(str) |
匹配字符串str |
(str1|str2) |
匹配字符串str1或str2 |
continuous match
pattern |
function |
|---|---|
char* |
重复零个或多个的前导符 |
char+ |
重复1个或多个的前导符 |
char? |
重复0个或1个的前导符 |
char{m, n} |
重复m-n个的前导符 |
备注
*, +, ? 称为限定符或数量符
贪婪和懒惰
pattern |
function |
|---|---|
*? |
重复任意次,但尽可能少重复 |