PytorchPractice
python
tensor-level
创建tensor
>>> torch.full((2, 3), 3.141592)
tensor([[ 3.1416, 3.1416, 3.1416],
[ 3.1416, 3.1416, 3.1416]])
torch.randn(*size) # 均匀分布,可接受位置参数
torch.randn(*size) # 正态分布
矩阵运算
# 含minibatch: A(10,3,4) B(10,4,5) C(10,3,5)
# 矩阵乘法
C = A @ B
# element-wise multiply
C = A * B
截断
import torch
out = torch.clamp(torch.Tensor([34, 54, -22, -9]), min=3)
# out:tensor([34., 54., 3., 3.])
数学运算
# 倒数:reciprocal
<Tensor>.reciprocal()
# 自然对数:返回(1+输入值)的自然对数
torch.log1p(...)
meshgrid
生成坐标点网格
y = torch.tensor([0, 1, 2])
repeat
repeat的复制操作是从右到左的;arg表示该维度上复制几次
>>> x = torch.tensor([1, 2, 3])
>>> x.repeat(4, 2)
# 先沿行 ×2
# i.e. 1, 2, 3 -> 1, 2, 3, 1, 2, 3
# 再沿列 ×4,得:
tensor([[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3]])
>>> x.repeat(4, 2, 1).size()
torch.Size([4, 2, 3])
reshape
tensor经过转置之后数据就不连续了,就不能使用view(),而需要先进行.contiguous()操作。reshape等价于.contiguous().view()
x = x.reshape(x.size(0), x.size(1), -1) # [B,C,8,8]->[B,C,64]
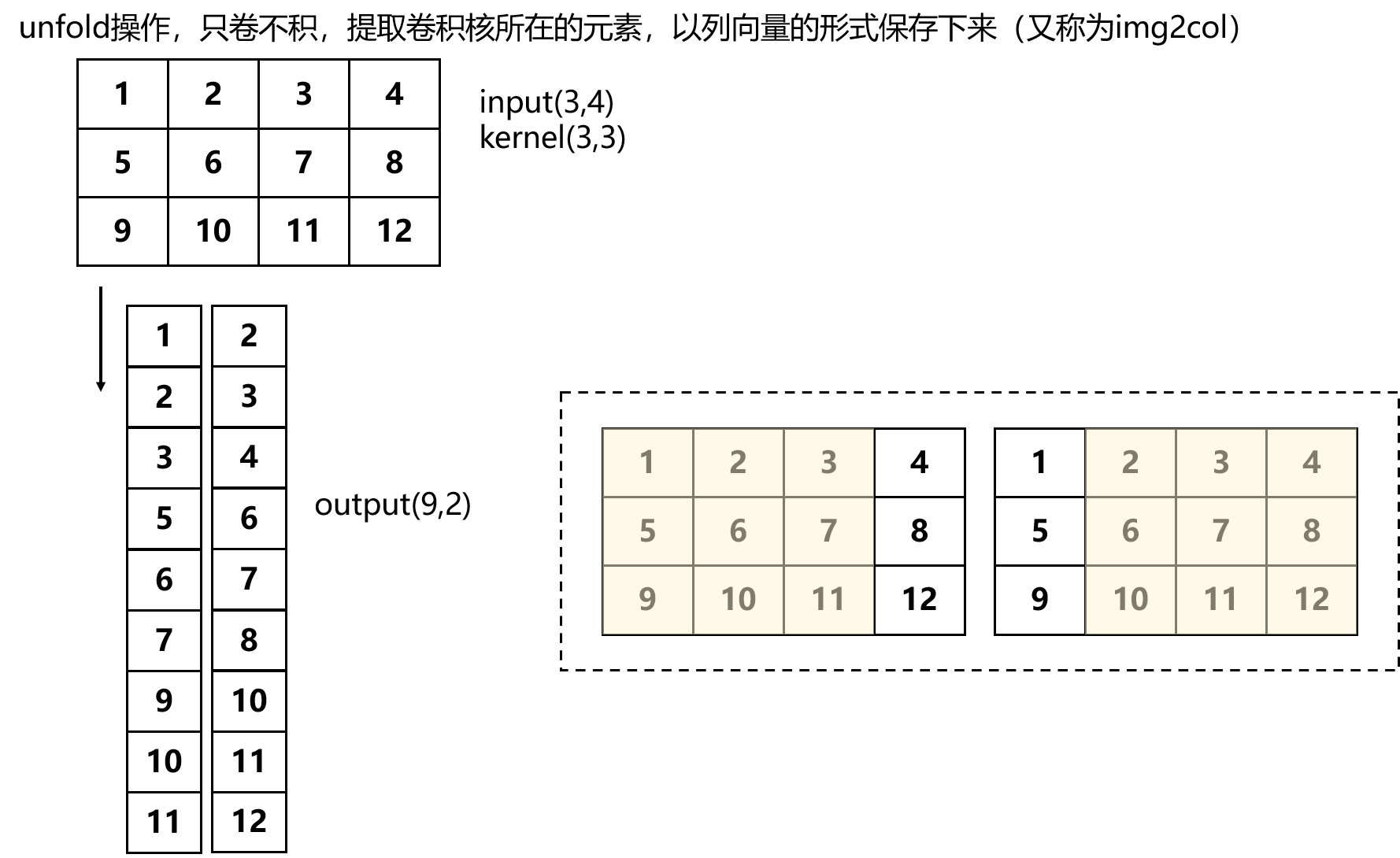
unfold
卷积=unfold(只卷不积)×矩阵相乘×fold
unfold操作:
import torch
import torch.nn.functional as F
import numpy as np
# "im2col_out_cpu" not implemented for 'Long' 即unfold操作不支持Long类型
img = torch.arange(0, 12,dtype=torch.float32).reshape(3, 4)
# input: [1, 1, 3,4]
# output [1, 9, 2] -> batch_size, kernel中的元素个数, kernel的个数
unfold = F.unfold(img[None, None, ...],
kernel_size=(3,3))
备注
其padding参数指的是在滑动窗口前先对矩阵边界进行padding操作
unsqueeze
None的作用:在所处维度中进行unsqueeze
import torch
tensor = torch.randn(3, 4) # torch.Size([3, 4])
tensor_1 = tensor[:, None] # torch.Size([3, 1, 4])
tensor_2 = tensor[:, :, None] # torch.Size([3, 4, 1])
最值
# 返回当前张量,前k个最大的元素
torch.topk(input, k, dim=None, largest=True, sorted=True, *, out=None)
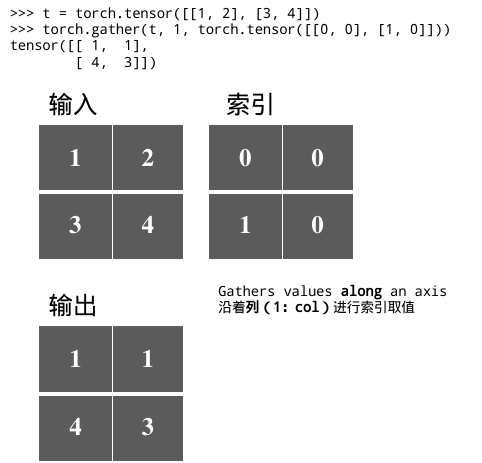
高自由度索引
input矩阵和index矩阵需要相同的数目的维度(如都是二维);另外index.size(d) <= input.size(d)
torch.gather(input, dim, index, *, sparse_grad=False, out=None) → Tensor
layer-level
池化
全局topK平均池化
# (B,C,H,W)
topk_num = 4
x = torch.arange(0, 24, dtype=torch.float32).reshape(1, 2, 4, 3)
x = x.reshape(x.size(0), x.size(1), -1)
_, idx = torch.topk(x, topk_num, dim=-1, largest=True, sorted=False)
y = torch.gather(x, dim=-1, index=idx)
agg = torch.sum(y, -1) / topk_num
>>> 9.5, 21.5
最大池化
self.max_pooling = nn.AdaptiveMaxPool2d((1, 1))
def forward(self, x):
feature_maps = self.resnet18(x) # (B,C,H,W) e.g. (20,512,8,8)
feature_vectors = self.max_pooling(feature_maps) # (B,C,1,1) e.g (20,512,1,1)
备注
注意有时可能需要去掉(1,1)
train-level
数据集预处理
from torch.utils.data import random_split
# 有布疵
training_setA, test_setA = random_split(defect_list, [1243, 533], generator=torch.Generator().manual_seed(233))
training_set = list(training_setA)
test_set = list(test_setA)
training_set = ["train/" + file_name for file_name in training_set]
test_set = ["test/" + file_name for file_name in test_set]
self.write_file(str(train_file), training_set)
self.write_file(str(test_file), test_set)
def write_file(self, file_name, contents):
with open(file_name, "w") as f:
for content in tqdm(contents):
f.write(content + '\n')
数据集划分
from torch.utils.data import random_split
subsetA, subsetB = random_split(range(集合的大小), [子集A需要划分的大小, 子集B的大小], generator = torch.Generator().manual_seed(42))
# e.g. 将有10350帧数据的数据集均分出一个训练集和验证集
# training_set, validation_set = random_split(range(10350), [5175, 5175])
备注
random_split() got an unexpected keyword argument 'generator',该API在1.7版本后才有
Dataloader
pytorch提供了Dataloader类来提供对数据集的shuffle,多进程,batch的操作
自定义数据集batch操作(在__get_item__时已完成了batch操作,而不需要再进行batch了)
from torch.utils.data import DataLoader
def collate_fn(data):
"""
自定义batch操作
"""
return data[0]
train_loader = DataLoader(train_dataset, batch_size=1, shuffle=True, num_workers=4, collate_fn=collate_fn)
微调模型
修改某一层(如修改resnet18的输入)
from torchvision.models import resnet18
from torch import nn
# 导入模型,由于任务差别大,所以不采用预训练
backbone = resnet18(pretrained=False, progress=True)
# 修改相关插件
backbone.conv1 = nn.Conv2d(in_channels=,
out_channels=,
kernel_size=,
stride=,
padding=,
bias=
)
优化策略
Adam, SGD
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001, betas=(0.9, 0.999))
self.optimizer_D_B = torch.optim.Adam(self.netD_B.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
# scheduler.step() # 随周期学习率进行衰减式更新
# optimizer.step() # 模型参数更新
hook获取feature map
def get_saliency_map(module, input, output):
"""
可视化feature map
:param module:
:param input:
:param output:
:return:
"""
saliency_map = input[0].clone().detach().cpu()
saliency_map = np.array(saliency_map)[0][0]
saliency_map = np.uint8(saliency_map * 255) # Scale between 0-255 to visualize
saliency_map = cv2.resize(saliency_map, (256, 256))
model.relu_featuremap.register_forward_hook(get_saliency_map)
参考资料:
Debug
验证调试模型输入和输出(用torchsummary可看更详细的输入输出信息)
model = USNet() # pretrained参数默认是False,为了代码清晰,最好还是加上参数赋值.
# print(model)
input = torch.randn(20, 1, 256, 256) # 打印网络结构
output = model(input)
# print(output.size())
print(output) # (20,2)
(类型错误)RuntimeError: result type Byte can't be cast to the desired output type Bool
[error] opp_labels = (box_preds[..., -1] > 0) ^ dir_labels.byte()
[right] opp_labels = (box_preds[..., -1] > 0) ^ dir_labels.bool()
(资源受限)RuntimeError:dataloader's worker is out of shm, raise your shm.
在docker中运行,资源受限,创建容器时加入--ipc=host或--shm_size=8G(默认是64M)
c++
安装
安装libtorch
根据对应的cuda,gcc版本进行安装(至少需要11.3)
最新的gcc应该使用cxx11 ABI
wget -c https://download.pytorch.org/libtorch/cu113/libtorch-cxx11-abi-shared-with-deps-1.10.2%2Bcu113.zip -O libtorch.zip
unzip libtorch.zip
NOTE
不使用最新的cuda版本或有如下错误(没该新的函数,from cuda11.3)libtorch_cuda_cpp.so: undefined reference to`cudaStreamUpdateCaptureDependencies@libcudart.so.11.0'
不使用cxx11而是用pre-cxx,会在cuda可执行文件链接时出现链接错误:
cuda_add_executable(<target_name> <file>.cu)
target_link_libraries(<target_name> ${TORCH_LIBRARIES})
# undefined reference to `c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)'
tensor-level
创建tensor
torch::Tensor tensorA = torch::arange(1, 10);
torch::ones(10, torch::dtype(torch::kFloat32).layout(torch::kStrided).device(torch::kCUDA, 1))
读写Tensor
创建Tensor
方法一:直接创建Tensor再在Tensor上赋值 方法二:创建好数组后再from_blob让Tensor指向该内存空间(效率更高)
访问Tensor
方法一:直接访问
方法二:accessor(效率更好)
备注
相关依据参考如下 测评
template
at::Tensor tensorA = torch::arange(1, 13, torch::TensorOptions(torch::kFloat32));
at::Tensor tensorB = torch::arange(1, 13, torch::TensorOptions(torch::kFloat32));
at::Tensor tensorC = tensorA + tensorB;
// template: dimensions number
auto tensorC_view = tensorC.accessor<float, 1>();
for (int i = 0; i < tensorC_view.size(0); i++) {
std::cout << tensorC_view[i] << std::endl;
}
// 判断其device
torch::Tensor tensor = torch::rand({3,4});
std::cout << tensor.device() << std::endl;
tensor索引
at::Tensor tensorA = torch::arange(1, 13, torch::TensorOptions(torch::kFloat32));
at::Tensor tensorB = torch::arange(1, 13, torch::TensorOptions(torch::kFloat32));
at::Tensor tensorC = tensorA + tensorB;
// tensorC[1:3]
auto tensorC_slice = tensorC.index({Slice(1, 3)});
auto tensorC_slice_view = tensorC_slice.accessor<float, 1>();
for (int i = 0; i < tensorC_slice.size(0); i++) {
std::cout << tensorC_slice_view[i] << std::endl;
}
// output:
// 4
// 6
python |
c++ |
|---|---|
[:,:,idx_list] |
{Slice(),Slice(),idx_list} |
CPU2GPU
auto cuda_available = torch::cuda::is_available();
torch::Device device(cuda_available ? torch::kCUDA : torch::kCPU);
<tensor_object>.to(device)
获尺寸
torch::Tensor tensor_rand = torch::rand({2, 3})
std::cout << at::size(tensor_rand, 0) << std::endl;
类型转换
template
// tensor类型转换
<tensor_obj>.to(at::kFloat);
// 构建张量时指定
at::Tensor votes =
torch::ones_like(topklabel_idx, at::TensorOptions(range_img.scalar_type()));
table
类型转换 |
描述 |
|---|---|
cuda->at::Tensor |
|
at::Tensor->cuda |
创建tensor后使用packed_accessor属性;核函数使用对应的参数 |
c++ arr->at::Tensor |
torch::from_blob() |
at::Tensor->c++ arr |
accessor |
hardware-level
判断GPU是否可用
auto cuda_available = torch::cuda::is_available();
torch::Device device(cuda_available ? torch::kCUDA : torch::kCPU);
std::cout << (cuda_available ? "CUDA available. Infering on GPU." : "Infering on CPU.") << '\n';
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
library-level
查看库版本信息
#include <torch/torch.h>
#include <iostream>
int main() {
std::cout << "PyTorch version from parts: "
<< TORCH_VERSION_MAJOR << "."
<< TORCH_VERSION_MINOR << "."
<< TORCH_VERSION_PATCH << std::endl;
std::cout << "PyTorch version: " << TORCH_VERSION << std::endl;
}
实战
打印tensor,看数据情况
#include <iostream>
#include <torch/torch.h>
using namespace std;
int main() {
at::Tensor tensor =
torch::arange(1, 13, torch::TensorOptions(torch::kFloat32));
cout << tensor.sizes() << endl;
cout << tensor.sizes()[0] << endl;
cout << tensor.size(0) << endl;
cout << tensor << endl; // 等价于 at::print(tensor);
}
// [12]
// 12
// 12
// 1
// ....
// 11
// 12
// [ CPUFloatType{12} ]
Q&A
model.eval()和model.train()的区别
前者能够使网络的BN层和dropout层失效
difference between Aten and torch library
Torch库算是Aten库的上层封装

其构建的Tensor有差别吗?没有,建议用torch namespace

// the same
torch::Tensor tensor_ones = torch::ones({2, 3});
at::Tensor tensor_ones_at = torch::ones({2, 3});
version compatibility
error: no matching function for call to ‘torch::jit::RegisterOperators::RegisterOperators(const char [28], <unresolved overloaded function type>)’
≥1.4的版本的pytorch将
torch::jit::RegisterOperators::RegisterOperators改为了torch::RegisterOperators::RegisterOperators
转置时数据在内存上是怎么变换的?
Tensor的数据存储时本质上是存储在一个一维数组上(称为Storage);要索引相关的值,则需要stride等属性。当进行转置时,Storage这个一维数组上的数值不变,只是修改stride属性。
Failed to compute shorthash for libnvrtc.so
find_package(PythonInterp REQUIRED)
CUDA error: invalid resource handle
这种方法仅适用于CPU的数据,对GPU数据做该种操作,则会有如上问题。

对核函数的返回值取from_blob,其值为0
对核函数的返回的数据无效,此cuda指torch的cu,而不是nvidia的cuda

utils
outline
tool |
description |
|---|---|
pytorch或会提供报错信息,但可能并不知道具体是哪个张量出问题,可用这个库来打印每个张量的shape, device, type信息 |
|
tensorboard |
可视化训练进展 |
查看模型参数和输入输出 |
|
模型可视化 |
snooper
import torch
import torchsnooper
@torchsnooper.snoop()
def myfunc(mask, x):
y = torch.zeros(6, device='cuda')
# Copies elements from source into self tensor at positions where the mask is True.
y.masked_scatter_(mask, x)
return y
with torchsnooper.snoop():
mask = torch.tensor([0, 1, 0, 1, 1, 0], device='cuda')
source = torch.tensor([1.0, 2.0, 3.0], device='cuda')
y = myfunc(mask, source)
tensorboard
安装
pip install tensorboard
可视化
tensorboard --logdir=<导出的文件夹名>
template
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="文件夹名",comment="后缀名") # 调用后即生成相应的文件夹
# 记录损失值
writer.add_scalar("Loss/train", loss, epoch)
write.close()
torchsummary
from torchsummary import summary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch v0.4.0
model = Net().to(device)
summary(model, input_size=(channels, H, W))