Numpy
向量操作
vector product
a = [1, 2, 3]
b = [2, 3, 4]
c = np.dot(a, b) # 14
c = a.dot(b)
matrix multiplication
a = np.array([1, 2, 3])
b = np.array([2, 2, 2]).T
c = np.matmul(a, b)
c = a.matmul(b)
c = a @ b
备注
不会严格地执行矩阵相乘,np会根据输入进行调整
e.g:有关广播机制
# 预期:
| 1 2 | | 1*1 2*1 |
| 3 4 | @ | 1 2 3 4 | = | 3*2 4*2 |
| 5 6 | | 5*3 6*3 |
| 7 8 | | 7*4 8*4 |
# 则需要先进行reshape操作:
reshape使广播机制成立,然后在向量广播操作后,可以使用hadamard积(element-wise)
广播操作:
| 1 1|
| 1 2 3 4 |.reshape(-1,1) -> | 2 2|
| 3 3|
| 4 4|
备注
广播操作需满足从最后一维开始,至少有一个维度的维数相同或者为1或者为0(scalar)
hadamard product (i.e element-wise product)
a = [[1,1],[2,2]]
b = [[2,3],[3,2]]
c = a * b # [[2,3],[6,4]]
cross: 向量叉乘
np.cross(A, B)
向量化操作
其向量化操作并不能提高速度,只是提高易用性

矩阵运算
求逆
# 求逆
np.linalg.inv(<矩阵>)
# 另一种形式为:np.matrix(<2D array>).I
# 求行列式
np.linalg.det()
# 解方程
np.linalg.solve(a<np.matrix>, b)
计算协方差矩阵
# (m,n) 共有n个数据,每个数据包含m个属性
# Each row of m represents a variable, and each column a single observation of all those variables. Also see rowvar below.
x1 = np.array([[1, 1, 2, 4, 2], [1, 3, 3, 4, 4]])
y1 = np.cov(x1, bias=True) # [[1.2 0.8], [0.8 1.2]]
注意
默认使用的是无偏估计(bias=False即/(n-1))
创建矩阵
零矩阵
# 传shape(tuple)
np.zeros((448,224,30))
# 初始化代价矩阵
iou_matrix = np.zeros((len(detections), len(trackers)), dtype=np.float32)
对角阵
# 自定义对角元
np.diag((2,3)) # [[2,0],[0,3]]
# 单位阵(方阵)
np.identity(2) # [[1,0],[0,1]]
# 非方阵
np.eye()
随机数
points = np.random.rand(100, 3) # 100 random points in 3-D
flatten
# Return a flattened copy of the matrix.
# All N elements of the matrix are placed into a single row. 保持原来维度
m = np.matrix([[1,2], [3,4]])
m.flatten() # matrix([[1, 2, 3, 4]])
# 返回一维
m = np.matrix([[1,2], [3,4]])
np.ravel(m) # [1, 2, 3, 4]]
结构体
import numpy as np
structure = np.zeros(3, dtype=[("colour", (np.uint8, 3)), ("label", np.bool)])
structure[0]["colour"] = [0, 218, 130]
structure[0]["label"] = True
structure[1]["colour"] = [245, 59, 255]
structure[1]["label"] = True
数据堆叠
np.stack(list)
# 水平方向的堆叠
extrinsic_matrix = np.hstack([rotation_m, tvec])
# 垂直方向的堆叠
extrinsic_matrix = np.vstack([extrinsic_matrix, [0, 0, 0, 1]])
一维数组的堆叠
# 如果array是一维数组(行向量:(N))则如下等价
np.column_stack( <arrayA>, <arrayB>) -> (N, 2)
np.hstack( <arrayA>.reshape(-1, 1), <arrayB>.reshape(-1, 1) ) -> (N, 2)
np.stack(( <arrayA>.reshape(-1, 1), <arrayB>.reshape(-1, 1) ), axis=1 ) -> (N, 2
# np.row_stack和np.vstack同理
Index
切片索引
# 表示索引倒数第一行第一列的数据
Mat(-1,0)
ATTENTION
在numpy中进行
切片索引时,应使用单括号和多逗号,不能用多括号
mask[1:2][3:4] ×
mask[1:2, 3:4] √
而索引单个元素时,则效果一致,没有区别e.g. array [0][1] == array[0,1]
np一维数组shape的表示为(N,)(含逗号)
arr = np.array([1, 3, 4, 5, 7])
>>> arr[1:-1] # 3, 4, 5(不包含7)
布尔索引
适用于构建mask,来对数据进行筛查
mask = (temp > 0) & (temp < 89.6) & \
(temp > -22.4) & (temp < 22.4)
pointcloud = pointcloud[mask]
索引变更
一维索引转为高维索引(Convert a flat index into an index tuple)
np.unravel_index([22, 41, 37], (7,6))
# (array([3, 6, 6]), array([4, 5, 1]))
# 22 = 3 * 6 + 4
# 41 = 6 * 6 + 5
np.unravel_index([31, 41, 13], (7,6), order='F')
# (array([3, 6, 6]), array([4, 5, 1]))
一般用于找高维数据最值的索引
[x, y] = np.unravel_index(np.argmax(2D_data, axis=None), 2D_data.shape)
数学函数
符号函数
# -1 if x<0
# 0 if x=0
# 1 if x>0
np.sign()
逻辑运算
# 按位与/或
np.bitwise_or(<bool_np_arrayA>, <bool_np_array>) # 等价于&
np.bitwise_and(<bool_np_arrayA>, <bool_np_array>) # 等价于|
类型转换
# only apply for scalar object
np.int/float()
# apply for numpy object (类型c++的static_cast)
().astype()
numA = np.float32(1)
numB = numA.view(np.uint32)
print(numB) # 1065353216(类似c++中的reinterpret_cast)
print(numA.astype(np.uint32)) # 1(类似c++中的static_cast)
属性
arr_np.flags.writeable # 读写权限
arr_np.flags.c_contiguous
arr_np.flags.fortran
arr_np.flags.f_contiguous
# The array owns the memory it uses or borrows it from another object. 是否是引用
arr_np.flags.owndata
随机数
import numpy as np
np.random.seed(233)
数据拷贝
repeat
沿着某个轴进行拷贝操作(只需要指定一个轴)
# (3, 3) -> (1000, 3, 3)
np.exapnd_(a, axis=0).repeat(1000, axis=0)
tile
沿着某个轴进行拷贝操作(需要指定所有轴)
points = np.random.rand(100, 3)
arr = points.reshape(1, 100, 3) # [1, 100, 3]
arr = np.tile(arr, (100, 1, 1)) # [100, 100, 3]
实战
numpy矩阵相乘运算cpu占用率大
进行矩阵运算时默认使用多线程进行运算,可以通过限制线程数来减少占用率(运算时间会提高)
os.environ["OMP_NUM_THREADS"] = "1"
import numpy as np
获取某个值的索引位置
np.argwhere(img == 255)
行向量变为列向量
# 方法一:
().reshape(-1,1)
# 方法二:
<np_array>[:, None]
# np.newaxis是None的alias
备注
对一维数组进行转置并不会生成(1,N)或(N,1)
Ellipsis 省略号
...是冒号':'的拓展,避免写多个:,如[:, :, 0]等价于[..., 0];索引时只能存在一个
numpy for matlab
分块矩阵的合并
import numpy as np
matA = np.arange(0, 12).reshape(3, 4)
mat = np.block([[matA, matA], [matA, matA]])
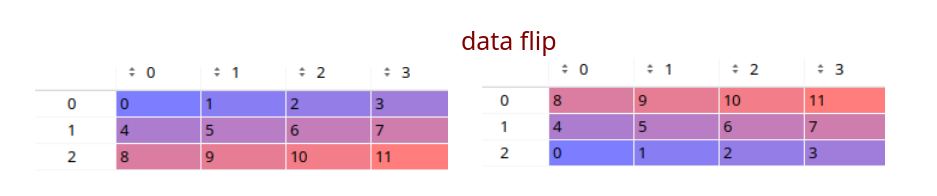
flip
A = np.arange(12).reshape((3,4))
B = np.flip(A, 0)
暴力搜索
import numpy as np
# 暴力搜索最近邻点:将目标点与其他点跟进行欧式距离上的比较
queries = np.random.rand(100, 3)
NN_distance = []
for i in range(len(queries)):
dis = np.linalg.norm((queries[i] - queries), axis=1)
idx = np.sort(dis)[1] # descending order
NN_distance.append(idx)
queries_mat = queries.reshape((-1, 1, 3))
targets_mat = queries.reshape((1, -1, 3))
distances = np.linalg.norm(queries_mat - targets_mat, axis=2)
min_distances = np.sort(distances, axis=1)[:, 1]
print(np.all(min_distances == NN_distance))
e.g. (100) -> ()
points_grid_min_dist_x = \
np.min(np.abs(np.tile(next_pc[:, 0], (len(x_grid_arr), 1)).T - x_grid_arr), axis=1)
points_grid_min_dist_y = \
np.min(np.abs(np.tile(next_pc[:, 1], (len(y_grid_arr), 1)).T - y_grid_arr), axis=1)
cost_vec = points_grid_min_dist_x + points_grid_min_dist_y